
The term Deep Learning(DL) seems quite fascinating and people often get confused between it and Machine Learning, so let me simplify it for you.
If you have read my previous blog on ML, you would have gathered that AI is really nothing more than the “ability of a machine to perform certain tasks based upon its previous experience, with the efficiency to carry out these tasks improving with every iteration and experience”.
So what is Deep Learning?
Well, it is a subclass of Machine Learning algorithms that uses multiple layers to progressively extract higher level features from the raw input.”
Deep Learning Definition (Wikipedia)
The basic feature which makes DL a class apart from other ML algorithms is the use of these layers which are made up of units called ‘Neurons’ – yes, you read that right, these neurons work similar to the neurons (nerve cells) in our brain and so the whole concept of DL is to replicate the human brain’s behaviour for processing data.
Let’s get into some Biology to get a better understanding of this architecture. The human brain consists of a network of neurons which transmit and receive neurological signals over a period of time as it processes data and this transmission of signals depends upon certain threshold barriers. Analogous to the neuron, the Perceptron forms the basic unit of the most common type of Neural Network, known as the Artificial Neural Network(ANN) and just like the ‘threshold barriers’, there is a mathematical function known as the ‘Activation Function’, which decides whether some piece of information is transmitted to the next neuron or not. See Towards Data Science article “What the Hell is a Perceptron”
Things seem to be getting a little too orthodox and boring right? Let’s understand this with the help of an example.
If you remember from my last blog, we learned how we used the Supervised Learning approach to gradually understand a friend’s handwriting which was almost illegible initially through repetition and guesswork. Now imagine that you are a teacher or a professor and you have tens or hundreds of such students, all having their own distinctive handwriting. While the above approach may solve our problem, it’s not practical to do so, isn’t feasible.
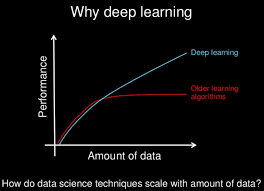
This is where the application of Deep Learning comes to the rescue! Deep Learning excels in the processing and analysis of larger data sets at much higher performance levels than older algorithms.
We can create a network of neurons similar to the ones in our brain and use them to process this information. This network is generally a Convolutional Neural Network(CNN), which is like an ANN but has some minute differences which makes it more efficient for image processing. The CNN basically consists of an input layer, an output layer and multiple intermittent hidden layers which have their own roles to play like pooling, convolution, etc. The dataset of handwritings is fed into the CNN and after training, Whoosh! We have our model which is completely capable of recognizing the letters for each person.
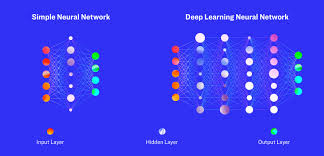
But how does this magic happen?
Here’s the answer to that – the neural network, consisting of neurons in different layers where the ‘weights’ and ‘biases’ assigned to each node is dynamically updated over time during training until it becomes satisfied with its own intelligence capability.
So doesn’t this sound similar to Unsupervised Learning?
Well sure it does but what distinguishes it from the former is the fact that even in an Unsupervised Learning model, we need to define the set of features which define the objects in our dataset, while in our Neural Network, it is just the data and nothing else which is fed into the model. The distinguishing features are also recognised by the network itself, thus not requiring any additional information from the user just as our brain would do.
You may ask then, why not just use Deep Learning models to solve all our AI problems?
Well, everything comes at a price and Deep Learning models are no exception. While these models are generally more efficient than their other ML counterparts, they require a lot of data compared to an ML model of the same scale. Not only does it require more data to train but also heavy computation and much more time (sometimes running into months) for training. This makes it practically impossible to train these models on our conventional CPUs and instead multi-core GPUs are preferred for this purpose, thus significantly increasing the cost as well.
So Deep Learning models are generally used in very critical projects where the cost can be traded off with a higher value of eminence like in autonomous vehicles where it is very crucial to correctly distinguish between a traffic light and a pedestrian.
In Summary
As complex as this may seem we’ve only just begun to introduce Deep Learning, it is indeed a deep and complex topic requiring a lot of time and effort to fully understand and master. It is a hot topic for research and is gradually coming into more and more use due to the advent of increasingly efficient and affordable GPUs in the market.
While there may not be any substitute for human intelligence, Deep Learning is definitely moving in leaps and bounds towards this goal.