
The Definitive Guide to what Cybersecurity Mesh Architecture (CSMA) should look like.
This is part 2 of a 3 part blog series about Data Mesh intended to educate and serve as a decision-making tool for security leaders rethinking their data strategy. You can read more in Part 1 and Part 3.
Dissecting Cybersecurity Mesh Architecture
Now that you have deeper familiarity with Data Mesh (from Part 1 of this series), it’s time to dissect CSMA (3.0) directly from Gartner. Where Data Mesh is about decentralization and enablement of distributed teams and has no prescriptive underlying infrastructure or technology constraints, CSMA is quite different. Even with the 3.0 revision to CSMA, Gartner is still explicitly prescribing centralization of data and control, with some light mentions of distributing enforcement points.
CSMA 3.0 (October 2025) does provide a practical framework for security tool integration through open APIs and data standardization. It attempts to solve for salient pains felt by security organizations: tool sprawl, compartmentalized signals, and inconsistent policies. In their Cybersecurity Leader Guide to Cybersecurity Mesh Architecture guideline for CSMA 3.0 from 24 October 2025, Gartner explicitly acknowledges “there are no complete five-layer single vendor CSMA solutions” and warns buyers to “[be] wary of CSMA marketing”. That forewarning is a large reason why we’re even authoring this whitepaper.
Despite borrowing the “Mesh” terminology, CSMA explicitly prescribes centralization, and you do not need to take my word for it. Directly from their terminology webpage, Gartner describes it as: “Cybersecurity mesh, or cybersecurity mesh architecture (CSMA), is a collaborative ecosystem of tools and controls to secure a modern, distributed enterprise. It builds on a strategy of integrating composable, distributed security tools by centralizing the data and control plane to achieve more effective collaboration between tools.” This is everything that Data Mesh is not, it is still integration and tool-centric whereas Data Mesh is domain-centric.
If you stretch the definitions and intent far enough, you could argue certain parts of CSMA are more similar to the Self-Service Data Infrastructure principle of Data Mesh. You will need composable elements of data infrastructure, you will need to integrate with certain tools (or data) that is created by Domain teams, and Data Mesh is collaborative as well. However, again, the terms are not interchangeable and that is what leads to a lot of confusion.
From 2022-2023 (CSMA 2.0 era) Gartner conducted a report across 200 security leaders, when asked “What are the main barriers to CSMA?” 51% responded that there was an unclear definition of CSMA. In this humble author’s opinion, I do not think that number would improve much with CSMA 3.0. In fact, I expect that would go up if the respondents also read this whitepaper – because “security mesh” is so different from actual Data Mesh.

Strip away the “mesh” terminology and CSMA describes API-based security tool integration with centralized orchestration and visibility. This solves tool interoperability problems, not organizational data ownership problems. CSMA is a service mesh for security tools, not Data Mesh for security data. CSMA explicitly prescribes centralization, that is not architectural innovation: it’s linguistic gymnastics to rebrand hub-and-spoke as peer-to-peer.
High-level information aside, there are now five Layers in CSMA 3.0, from an original four Layers in CSMA 1.0/2.0. I’ll outline the descriptions from Gartner, highlight differences from Data Mesh, and expand upon the Layers with examples as I did in the previous section on Data Mesh Principles.
Security Analytics Intelligence Layer
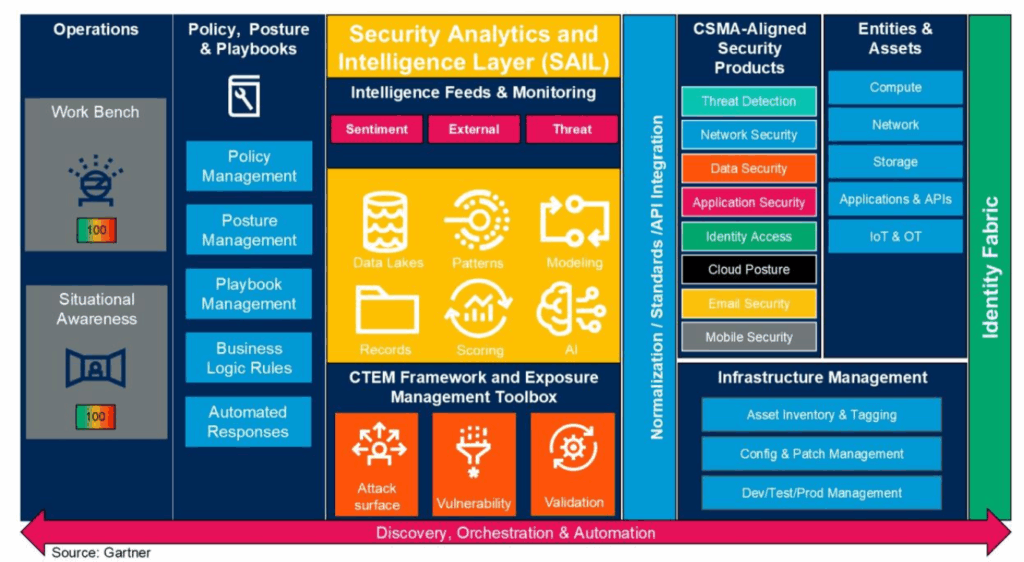
The Security Analytics Intelligence Layer (SAIL) is focused on centralization of threat analysis, risk scoring, and other security analytics (e.g., AI, ML, Statistical, etc.) across all of your interconnected security tools in your CSMA. It includes (mostly external) Cyber Threat Intelligence (CTI) feeds – such as IOC- and TTP-based data – as well as sentiment based analysis of the data. Additionally, it includes provisions for Cyber Threat & Exposure Management (CTEM) toolchain integrations for External Attack Surface Management (EASM) and Threat & Vulnerability Management (TVM) data, along with any validation and deduplication efforts.
Ostensibly, SAIL is meant as your centralized source of truth & system of record for any asset and/or entity posture, similar to what graph-based Cloud Native Application Protection Platforms (CNAPPs) are intended to be used for. You decompose and disseminate intelligence information (that hopefully aligns with Priority Intelligence Requirements) about external attackers, exploits, and weaknesses against your own asset posture, supplemental data (network, identity, ownership, data, code), and use it for extended analytics for prevention and/or remediation efforts.
SAIL’s requirement to “centralize threat analysis and risk scoring” begs the question: what infrastructure would actually implement this layer? In practice, organizations would likely repurpose existing SIEMs, XDRs, or TIPs – creating the same tool ownership and data centralization challenges that already plague security operations. Gartner doesn’t prescribe specific tools, which creates ambiguity about who owns SAIL and how it’s actually built.
This critique will remain relatively similar across all CSMA Layers, however SAIL is all about centralization of data across different Domains, and there is not a single mention for being Domain-centric nor functional-centric at all. There is not an architectural quantum to be found, as largely SAIL seems to be predicated upon the right blend of security point solutions and a centralized security organization collecting all of this data for the jobs to be done. However, there are several jobs to be done with this data, straddling several different subdisciplinary lines within a typical security team.
There’s no concept of analytics domains (TVM analytics, IAM analytics, endpoint analytics) owning their analysis as products. Instead, all security data flows into this central layer where someone else – the SOC, I suppose – figures out meaning and correlation. This recreates the exact bottleneck Data Mesh solves. Additionally, there is no mention of the application of any governance is this layer, despite the following key actions being called out:
- “Designate which tools will become the desired “source of truth” across each security aspect and determine their level of support for open standards and integrations with open API and OCSF.”
- And, later on in another subheading (Avoid Vendor Lock-in With Open Standards): “Favor vendors who adopt recognized industry standards, like the OCSF.”
With OCSF as an agreed upon interoperability standard, SAIL would be much stronger with Federated Computational Governance Principles layered in. Perhaps that is implicit, but at the very least, that sort of thing should be called out as all policy and governance language largely has to do with security policy-based governance such as DLP policies, authorization, and other similarly themed factors. Outside of Amazon’s own Security Lake product, there are very limited OCSF validation and enforcement layers, and not using a standardized data model would complicate what is already a complicated project that most fail at. SAIL is rebranding what has been tried previously with UEBA, SOAR, XDR, and even SIEM itself. However, SAIL doesn’t exist on its own, and actually inherits much of its data from the next Layer, Infrastructure Management.
Infrastructure Management Layer
The Infrastructure Management Layer (IML) is not to be confused with the Data infrastructure provisioning plane (DIPP) of the Self-Service Data Infrastructure Principle from Data Mesh. The IML is your asset inventory and configuration management layer – tools that track what you have, where it is, and how it’s configured. Think asset discovery tools, CMDB (ServiceNow), cloud asset management (CloudQuery, Orca Security, Wiz, Cisco Panoptica), vulnerability scanners, and patch management systems. It’s meant to provide the “what needs protecting” context to the other Layers.
To me, this is where a large portion of the data centralized into the SAIL comes from, specifically for CTEM context. It’s an important part of the overall security intelligence cycle, and echoes a mantra that many of us have heard throughout our collective careers: you cannot protect something you don’t know about. Stepping away from the implicit issues this presents due to incomplete sensor coverage, incompatible platforms (due to OS versions, hardware, kernel versions, etc.), and general “Shadow IT” issues that persist in many large organizations, there is still no concept of ownership here.
In a Data Mesh, there would be an Infrastructure Services Domain that would own all of the data products for the CSMA IML, they would be the ones responsible for wrangling, rectifying, collating, and deduplicating asset data wherever it lives. You have a portion of this data for cloud, virtualization, and on-premises assets coming from your EDR tools, your MDM/MEM tools, any patch management tools, CSPM/CNAPPs, and even in DSPM, DLP or AppSec tools that enumerate the various ways an “asset” can be defined in an organization. Without a single Domain team being responsible and accountable for producing this Data Product, and without leadership mandates for coverage and collapsing redundant or incompatible tool chains, this function will likely have a high rate of failures.
This is where an interoperability standard such as OCSF would actually come into play, notably with the User Inventory Info, Device Inventory Info, Software Inventory Info, and Cloud Asset Inventory Info event classes. The Data Product produced would be fully enriched and deduplicated data normalized into one or more of those Event Classes, based on agreement from the various other Domain teams who rely on this data. Federated Computational Governance would enforce this through validation against the schema, and the Infrastructure Services Domain team would be responsible for this end-to-end; perhaps using DIPP-provisioned pipeline, streaming, and Change Data Capture (CDC) blueprints from the SecDataOps team’s Self-Service Data Infrastructure.
The data doesn’t need to be centralized into the SAIL, if there was a Security Analytics & Intelligence Operations Domain team, they could consume the Asset data Product from wherever it was served up instead of the necessity of centralized storage as defined in CSMA 3.0. Either way you look at this, the IML lacks any of the Data Mesh principles and is a further example of rebranded hub-and-spoke without any clear ownership or success metrics tied to it.
To be clear: Data Mesh doesn’t eliminate the need for centralized asset inventory – it elevates it to a first-class domain with clear ownership and accountability. The Infrastructure Services Domain would still produce a unified asset inventory data product, but they’d be empowered and accountable for its quality, not just custodians of a centralized database someone else manages
To further complicate comprehension, in the same Cybersecurity Leader Guide to Cybersecurity Mesh Architecture guide, Gartner recommends that you establish a common data fabric for cybersecurity, further expanding that “Disparate cybersecurity tools generate data in different formats, making it challenging to see threats clearly or respond quickly. A common data fabric solves this by normalizing information across all sources so your team can analyze activity holistically and act on real signals instead of noise”. Data Mesh? Data Fabric? “Which one is it?” you may ask.
Data Fabric refers to the technology infrastructure for integrating distributed data sources – which is a lot of what Query provides. When it comes to Data Mesh, Data Fabric is complementary: Data Mesh defines who owns data products and their accountability; Data Fabric provides the infrastructure for consumers to access them. While our critique focuses on CSMA’s misuse of “mesh” terminology specifically, data fabric is used appropriately in this context. It is the how and not the what.
There are many flavors of Data Fabric out there, some of them are more use-case specific such as Avalor Security (acquired by ZScaler), there are some Security Data Pipeline Platforms (SDPPs) such as Monad that have use-case specific pipelines that could enable a Data Fabric, and Query itself could be more easily defined as a Data Fabric than a Data Mesh, like I said, we muddy the waters by straight up calling a platform a Data Mesh.
So yes, you should build or use a Data Fabric to enable your Data Mesh, even if it’s only CSMA. Security teams are not always well equipped to handle the data engineering challenges that it takes to be a proper Domain team. OpenText defines Data Fabric as: “…an architecture that facilitates the end-to-end integration of various data pipelines and cloud environments through the use of intelligent and automated systems. Data orchestration can be seen as a crucial element in implementing a data fabric. It provides the mechanisms for managing and coordinating data flows within the fabric, ensuring that data is accessible and usable across different environments and applications.”
I think that is an apt description of the intent of a Fabric, which is to say that Gartner is using the term correctly, and it’s a good recommendation overall. This definition comes up in their next Layer, the Identity Fabric Layer.
Identity Fabric Layer
The Identity Fabric Layer (IFL) is essentially your entire Identity, Entitlements, and Access Management (IDEAM) stack. Encompassing Identity Providers (Entra ID, Okta, Google Workspace), Privileged Access Management (PAM), Identity Governance (IGA), and all other authentication and authorization systems and tools. I actually agree with the usage of “fabric” in this Layer, it’s appropriate as the intention of this layer is the application and provisioning of consistent identity and access context of all IDEAM security controls, to all assets regardless of where they live.
My assumption is that the IFL is meant to ensure that human and machine identities can interoperate across the CSMA, and that’s a good idea. I’ve worked in and with many organizations that have multiple IDPs, and several overlapping or slightly competitive IAM security solutions in their organization. It is only to your benefit to ensure you have a tightly controlled IDEAM landscape, both for data security and overall data access. How many attacks and breaches have we seen caused by improperly configured or overly permissive IDEAM technology stacks?
IFL is more closely related to “Zero Trust” where one of the key principles is to assume breach, it’s in the name, you don’t explicitly trust any human or machine identities. Authentication and authorization across identity and network boundaries are constantly rechecked, identities should only have minimum necessary permissions, and access is segmented as much as possible. It is unclear to me if IFL is meant to also be similar to IML, except instead of assets it has to do with Identities, or if Identities are also an asset class in terms of CSMA.
Whichever way you take this, this Layer like the others above it is bereft of Data Mesh Principles. In a Data Mesh rollout, an Identity Services (or, IAM Security) Domain team would own all of the analytical data coming from this layer explicitly. They would work to expose details on authentication, authorization, PIM/PAM, IGA, and user asset data that is needed for consumption by other domain teams. They may use a Data Fabric for this, or some other DIPP-provisioned infrastructure provided by the SecDataOps teams and land it in an agreed upon location that the Domain team can interoperate with easily.
IFL appropriately uses “fabric” terminology because identity should be consistent across environments – this is fundamentally different from data, which benefits from domain-specific ownership. Where IFL falls short isn’t in its centralization of identity policy (which may be necessary), but in its unclear relationship to data governance. Does the IFL also govern data about identities – authentication logs, authorization events, privilege changes? The layer description focuses on operational identity management but doesn’t address who owns identity telemetry as a data product. This ambiguity exemplifies CSMA’s tool-centric rather than data-centric worldview.
What is more confusing, is there is seemingly some overlap with the fourth Layer, the Centralized Policy, Posture, and Playbook Management Layer.
Centralized Policy, Posture, and Playbook Management Layer
The Centralized Policy, Posture, and Playbook Management Layer (C3PM) is all about operational governance and policy enforcement, not data governance, but typical Policy-as-Code (such as OPA or HashiCorp Sentinel), posture management, and SOAR/AIR (AI Response) playbooks. Think of tools such as Torq, Tines, Swimlane, Splunk SOAR, Palo Alto Cortex xSOAR, or even runtime-specific tools such as API Security, Secure Access Service Edge (SASE), or Cloud Access Security Brokers (CASB, such as MCAS or Skyhigh Networks).
Much like the concept of IFL, C3PM seeks to centralize consistent security policies across your tool portfolio, (implicitly) govern what “good” posture looks like, and also centralize the orchestration of automation and remediation based on those signals. This has been somewhat of a “Holy Grail” for the security industry even going back several decades to the Unified Threat Management (UTM) days, and beforehand. A way to ensure that all of your desktop, mobile, and SaaS is treated the same across AMD and ARM architectures, across any operation system, in all environments. Use that likewise treatment of policy and configuration to automatically revert or update assets into a “known good” state as a preventative precursor to more “hands-on” activity.
C3PM conflates two distinct types of policies: operational security policies (DLP rules, access controls, incident response playbooks) and data governance policies (schema validation, data quality SLOs, interoperability standards). The former may benefit from centralization – consistent DLP policies across endpoints make sense. But CSMA applies the same centralization philosophy to data, which is precisely what Data Mesh’s Federated Computational Governance avoids. There’s no mechanism for domains to set local data policies within global constraints, because CSMA doesn’t have domains in the first place.
If you were to put a more Data Mesh focused lens on this, obviously your Domain teams would agree to and apply whatever Federated Computational Governance was required. That would strictly be for data, however, security policies are mentioned as an explicit requirement as per the diagrams and prose written on Data Mesh on the Data Mesh Architecture website. Your various Domain teams such as the EDR Domain, TVM Domain, and otherwise in a security-centric Data Mesh would be responsible and accountable for furnishing the analytical data for their domain, but also retain the security ownership outside (you know, the first part of SecDataOps). They would need to pick what security configuration, authorization, and access policies (such as using Microsoft Intune, JAMF Pro, OPA, Sentinel, MCAS, etc.) and separately handle the data engineering side to ensure the results of these policy enforcement and playbook execution events are available.
That is really the only way to rationalize these two disparate concepts – security and data – into one cohesive unit. We are seeking enablement, not further centralization and compartmentalization. That brings us to the final layer, the Operations Dashboard Layer.
Operations Dashboard Layer
To me, the Operations Dashboard Layer (ODL) is the vaunted “single pane of glass” that has been attempted by several companies across several cybersecurity and GRC market segments. Be in GRC Platforms (Archer, Vanta, Drata), Cyber Risk Quantification (ThreatConnect), Security Campaign Management/Security Performance Metrics Platforms (Seemetrics), or even custom PowerBI dashboards – nearly every security organization of nearly every size as tried this. Whether it’s a SOC metrics dashboard, a CISO executive dashboard, or a Security PMO dashboard – I am almost willing to wager that you have had to build one, or provide the data for it.
The “single pane of glass” is the opposite of Self-Service Data Infrastructure. Even with Gartner’s recommendations for automation and open APIs, a centralized ODL creates an architectural bottleneck: someone must decide which metrics appear on whose dashboard, how data is aggregated, and when refreshes occur. In Data Mesh, consumers self-serve these decisions – the TVM domain team builds their own dashboards against their own data products, the SOC builds theirs, executives build theirs. When a downstream schema changes, it impacts only the domain that owns that data product, not every dashboard in the organization. ODL centralizes not just the data, but the decision-making about how to consume it.
This harkens back to my commentary of SDPPs and other centralized tools, be they XDRs, CNAPPs, SIEMs, or otherwise adding more brittleness. You exchange some accountability and responsibility on your RACI to a vendor, and are beholden to sources they support, accuracy, timeliness, and overall trustworthiness of the data that they produce. If a downstream schema change happens – be it at the first line vendor’s API, or in your database – the data in your dashboard outright breaks or is no longer (contextually) accurate. Every ETL and enrichment stage your data moves through adds more latency, more chances for some dimension or feature of the data to change, and ultimately makes your reporting dashboards a past-tense tool. This is not actionable intelligence, in fact, it’s hardly intelligence at all.
This really highlights the importance of Domain Ownership and Data as a Product within the Data Mesh. If multiple parties are accountable for furnishing data, then no one is really accountable. If you have to constantly furnish data to support these massive dashboards, or even a SAIL concept, you’ll consistently be looked at as the bottleneck at best or a detriment to overall security operations at worst. This is why you must have Domain Teams responsible for the full spectrum of producing the Data Product, there needs to be ownership (and dare I say, esprit de corps) tied to your SecDataOps efforts. Likewise, consumers should be pushed to consume these data products for their own end. Maybe you cannot force your typical F500 CISO to get into the DIPP or DPDXP within your Self-Service Data Infrastructure to provision a Streamlit instance or Amazon QuickSight Analytic, but someone certainly can.
Closing Thoughts on CSMA
To me, CSMA is just more of the same. If we look over what Gartner is saying about the benefits, I don’t see how this is any different or revolutionary from what has always been talked about or promised.
- “Integration between products happens faster with less manual work…”
- “Teams spend less time troubleshooting tool compatibility or moving data between silos because of the unified data model and data centralization.”
As laid out in the previous major section about Data Mesh, collaboration and decentralization are as effective – if not more effective – than centralizing all of your data. Haven’t we tried that before? UTMs, SIEMs, UEBAs, XDRs, CNAPPs, and vendor-specific flavorings of security data lakes and lakehouses. They have and will continue to work for some, but not all deployments. What is more important is the right people and the right processes, and holding teams accountable for their success, with the proper metrics and expectations set. If you followed the CSMA Layers to the last dot, without the sociotechnological discipline from a proper Data Mesh, I fail to see how this proposal is any different than what has been done.
If there is one benefit that I draw major issues with (obviously), is this:
- “Threat detection improves because signals are shared across all layers instead of being trapped in one product, eliminating the data silo problem or utilizing federated search and discovery features.”
Remember that 51% of security leaders in Gartner’s own 2022-2023 survey cited “unclear definition of CSMA” as a barrier. This confusion isn’t accidental – it’s the natural consequence of borrowing Mesh terminology for what is fundamentally hub-and-spoke architecture. When you must centralize data to achieve ‘interoperability,’ you haven’t solved the silo problem – you’ve just traded many small silos for one large one, with all the access control, scalability, and ownership challenges that implies.
Gartner claims CSMA involves “distribution of individual enforcement, decision, and policy points” – but this refers only to operational enforcement (firewall rules, endpoint agents), not data architecture. The data and control planes remain explicitly centralized. This is like claiming a CDN is “distributed” because it has edge nodes, while ignoring that all content originates from a central origin server. True distribution, as in Data Mesh, means domains own their data products end-to-end, not just where enforcement happens.
Cost pressures, internal inertia (resistance), and doctrinal adaptation cycles will not make CSMA (or any centralization) a reality overnight. That is where a proper Data Mesh is at an advantage because at the onset you’re already agreeing to not centralize, which is the most expensive part. So saying you don’t need federated search and that you will immediately have a miraculous turnaround in your threat detection efforts is a serious miscalculation made by someone who has never done this work (at best), or an outright lie.
Implemented correctly – whether with Query or someone else – federated search solutions gives you the flexibility to treat distributed and decentralized data as if it were centralized. There are certain datasets that make sense to stay behind their APIs or in their data lakes as “sources of truth”, don’t take my word for it, Gartner makes the same recommendation: “Designate which tools will become the desired ‘source of truth’ across each security aspect and determine their level of support for open standards and integrations with open API and OCSF.” That is a great selling point for an OCSF-native Security Data Mesh (or, Data Fabric), just like Query.
To put a finer point on it, let’s say you are a SOC analyst investigating a suspected data exfiltration and you need to answer: “Did this compromised service account access any sensitive S3 buckets in the 48 hours before we detected the compromise?” In a traditional tool-centric model – CSMA, or otherwise traditional SIEM-based models – you have to collect, collate, and correlate data from the following sources (and more):
- IAM authentication logs from Okta (~90-day retention, behind API) and specific identity federation and authentication (AssumeRole, AssumeRoleWithWebIdentity) records from AWS CloudTrail
- Cloud access logs from AWS CloudTrail, which can be in Amazon Security Lake, CloudTrail Lake, or using the Event History UI/API
- Data classification metadata from DSPM tool such as Cyera or Sentra
- Service account inventory from ServiceNow CMDB tables and from Okta or Entra ID
In the CSMA model, based on what Gartner prescribes, you are operating under the assumption that you have 100% of all the logs with full fidelity, and hopefully the logs are standardized on OCSF (or otherwise) such that common identifiers, IOCs, actions, and failure states are normalized to common fields. If not, then in most organizations your investigation may turn into an absolute slog.
- Week 1: You discover you need Okta auth logs in SAIL, but SecDataOps hasn’t ingested that source yet. You submit a change ticket to SecDataOps to add Okta pipeline to SAIL
- Week 2-3: SecDataOps conducts exploratory data analysis of Okta’s system log, negotiates access with the CIO organization, develops an ETL pipeline, and writes transformation logic for OCSF mapping
- Week 4: The Okta pipeline goes live, but only pulls the last 30 days of data from the API, and now you missed the 48-hour window by 3.5 weeks.
- Week 5: Analyst discovers CloudTrail logs in SAIL lack the bucket-level detail needed, since they’re only Management Event logs and not S3 Data Event logs
- Week 6: Submit another ticket to re-ingest CloudTrail with full fidelity – SecDataOps begins the work of working with the Cloud Management Platform team and IT Financial Management on enabling S3 Data Events.
- Week 8: The request is likely denied due to cost, the incident trail is now 2 months old, evidence is cold, and the attackers have moved on.
Potential direct costs just in S3 storage of the staging data can reach several 10s of 1000s of dollars, even smaller organizations can produce several terabytes per day (if not per hour) and at $23/TB/Month in Amazon S3 minus other costs you’re beholden to what you thought you need already. If you have to rewrite pipelines, redrive logs, or onboard new sources your time horizon increases. Heaven forbid the data you need didn’t exist already, and isn’t retained long enough by a vendor, you will never get the answers you need. Let alone the indirect costs of the ~80+ hours of change management, meetings, and data engineering work from the central SecDataOps organization.
Now, let’s say you ignore CSMA entirely or discard the notion that centralization means you do not need federation at all. Your workflow using the Query Security Data Mesh platform could look like this:
- Minute 1: Analyst writes FSQL query joining across OCSF Authentication, API Activity, and Data Security Finding event classes, looking for the bucket name and/or (service) account name.
- Minute 2: Query federates execution in parallel:
- Translates to Okta API query syntax
- Translates to Athena SQL for CloudTrail in S3/Security Lake
- Translates to DSPM vendor API calls
- Translates to ServiceNow CMDB API query
- Translates to Entra ID OData (or Azure Data Explorer/Azure Log Analytics KQL)
- Minute 3: Results stream back with OCSF-normalized data, showing 3 suspicious bucket accesses
- Minute 8: Analyst iterates through pivots to refine timeframe, collect collated results, and prepare to open a new Incident (e.g., ServiceNow SIR, Microsoft Sentinel, etc.)
- Minute 15: Analyst pivots to investigate those 3 buckets, queries DSPM for sensitivity labels and access patterns more broadly
- Hour 1: Incident scope identified, containment initiated
While this does not account for the worst case scenario – a key log source hasn’t been onboarded – using the power of a Data Fabric that accesses decentralized data where it lives, handles all normalization, parallelization, and query translation for you to enable a Security Data Mesh seems to solve everything CSMA purports to provide without the centralization tax.
| Factor | CSMA Centralization | Data Mesh + Federation |
| Time to Answer | 8 weeks | <1 hour |
| Engineering Cost | 80+ hours | 0 hours |
| Storage Cost | +$15K/year | $0 |
| Data Freshness | 2 months stale | Real-time |
| Org Friction | Multiple tickets, approvals | Self-service |
| Brittleness | Pipeline breaks on schema change | Query adapts automatically |
| Next Similar Question | Another 2-4 week cycle | <5 minutes |
At the end of the day, integration in CSMA is not faster, it can take days or weeks from initial scoping to furnishing the data sources into the SAIL. Signals are not shared, but delayed by the time data reaches the SAIL, it’s stale, with orders of magnitude dependent on how much enrichment and latency occurs throughout the pipelines, streaming infrastructure, and otherwise. Finally, you haven’t eliminated any siloes by using a centralized-first approach with CSMA, you’re back to where you started: as a bottleneck.
In a federated model, that same analyst writes one OCSF-based query (if using Query) that executes across all four sources in parallel, gets results in under a minute, and iterates their investigation in real-time. This isn’t a hypothetical – this is the daily reality of security operations. Centralization doesn’t “eliminate the data silo problem” as Gartner claims – it just trades many fast silos for one slow silo.
If you’re considering your security data strategy and want to explore the benefits of a decentralized approach, reach out to us. SecDataOps savages are standing by…
Stay Dangerous.
This is part 2 of a 3 part blog series about Data Mesh intended to educate and serve as a decision-making tool for security leaders rethinking their data strategy. You can read more in Part 1 and Part 3.