Security Data Is Piling Up.
Moving It Shouldn’t Be So Hard.
Sometimes you just need to move data. Security teams use telemetry from dozens of sources. When it’s time to store, search, or analyze that data, things break down. SIEM costs explode. Custom pipelines get brittle. And most so-called “data platforms” just add complexity.
Query Security Data Pipelines were built to send the right data to your choice of storage, according to best practices and ready to use.
A Better Way to Move, Normalize, and Store Your Security Data
Query Security Data Pipelines are a simple way to move telemetry from your endpoint, network, identity tools, and more into storage, without managing brittle ETL jobs or buying heavyweight infrastructure.
Data lands clean as compressed Parquet, partitioned for performance, and structured for downstream search, compliance, and analytics. You get full control over what data moves, how often, and how far back to go all without worrying about transformations or mapping.
It’s everything you need to write to the gold layer of your security lake, without the overhead.
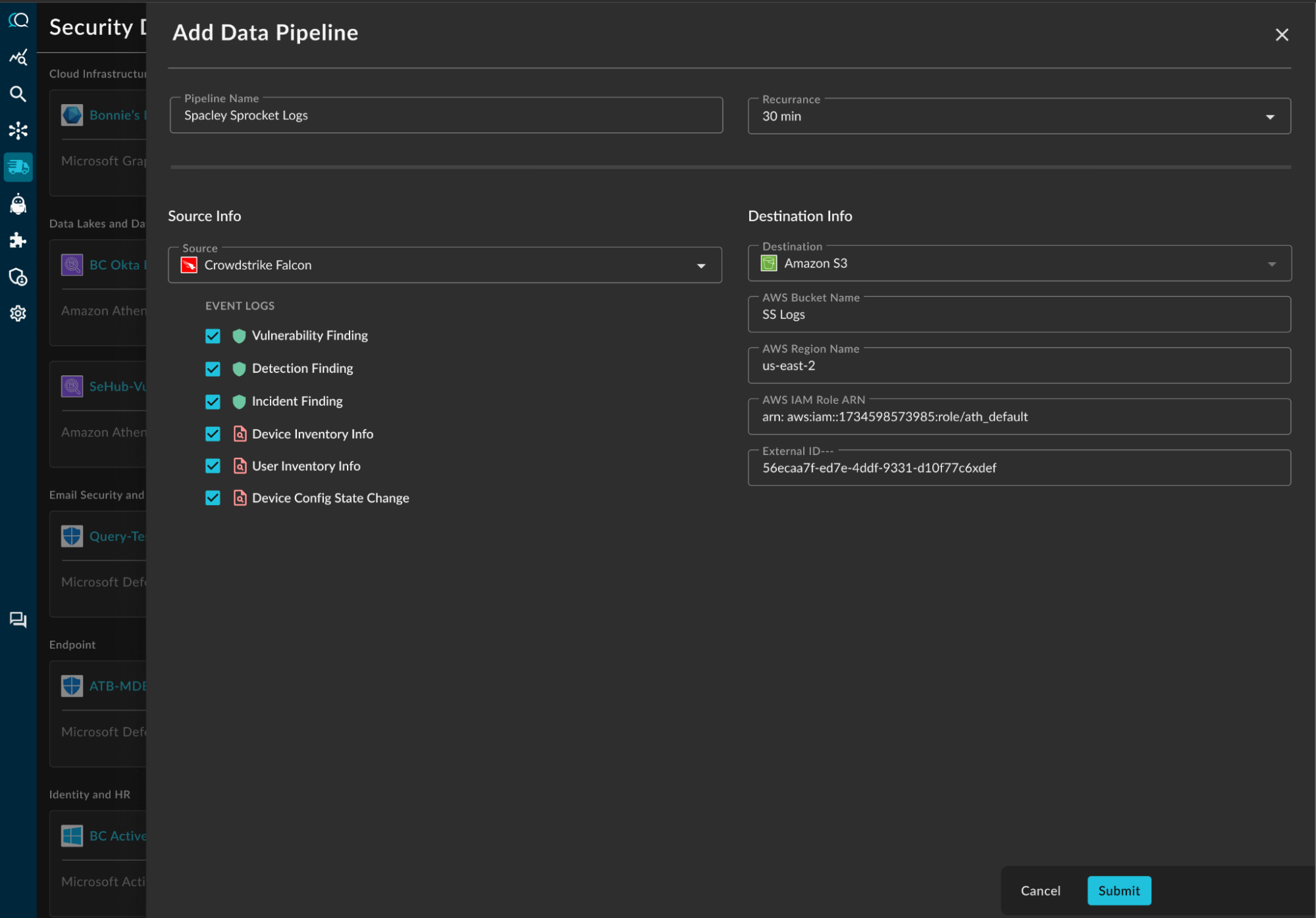
Built To Do the Hard Work For You

Automatically move telemetry from source to storage
Connect tools like CrowdStrike, Entra ID, GitHub, and more. Schedule delivery directly to your own storage with just a few clicks and no custom scripts or middleware.

Land data in compressed, partitioned Parquet
Data is written in ZSTD or Snappy-compressed Parquet, partitioned by time and event type using Hive-style folders. Ideal for query engines like Athena, Redshift Spectrum, Snowflake, Azure Data Explorer, and, of course, Query 😁

Keep your lake clean and future-proof
No more raw JSON or messy nested arrays. Query normalizes data automatically behind the scenes, so what lands is structured, ready to use, and built to scale.

Handle historical hydration on setup (coming soon)
Choose how many days of data to backfill when setting up a new pipeline, so you’re not starting from zero.

Control what, when, and how data moves
Choose which sources to activate, how often data should be written, and how far back to hydrate. (Coming soon: select specific events and fields before write time for even more control).

Skip brittle ETL jobs and parsing overhead
No packs to install and configure, no hand-coded transforms, no YAML or JSON defined mappings. Just decide what you want to move, how often, and Query handles the rest.
Set It Up Once. We Handle the Rest.
You pick the source, destination, and schedule. Query does the heavy lifting of normalizing, partitioning, and writing your security telemetry to cloud storage in the right format, with zero pipelines to maintain.
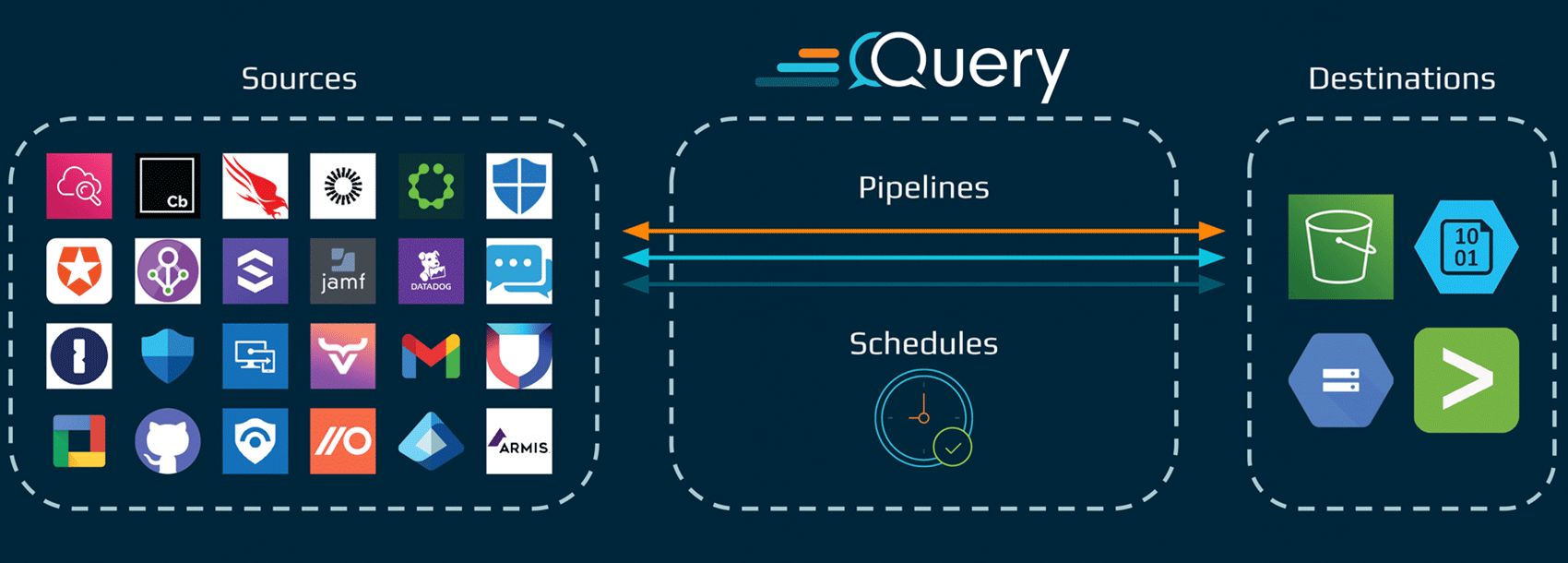
Pick your data source
Choose from supported Sources like CrowdStrike, Entra ID, GitHub and more. Query handles event collection and schema alignment automatically.
Choose your destination
Send data to Amazon S3, Azure Blob (ADLSv2), Google Cloud Storage or Splunk today, with support for Snowflake, Databricks, Amazon Security Lake and more coming soon.
Set your schedule
Define how often to deliver new data (e.g., every hour or every 30 minutes).
Query runs the pipeline
Pipelines are orchestrated with cloud-native services on our infrastructure. No containers to manage, no custom code to write.
Data lands clean
Structured Parquet. ZSTD or Snappy compression. Hive-style partitions by source, event type, and time. All ready for whatever comes next: search, analytics, AI, or compliance.
What Changes When You Turn It On
From SIEM offload to storage savings, Query Security Data Pipelines help you move more data for less and actually make it usable when it gets there.
80%+ reduction in storage footprint
Thanks to ZSTD-compressed Parquet with partitioned delivery, greatly reduce storage volumes versus JSON, XML, or other standard outputs from “the other guys”
<5 minutes to set up a pipeline
No YAML, no packs, no custom jobs; just Source, Destination, Schedule.
Offload Logs, Shrink Your SIEM Bill
Offload bulk telemetry to your own cloud storage and shrink your SIEM bill fast.
No more broken ETL pipelines
Query handles collection, normalization, and delivery using cloud-native orchestration. There are no “packs” nor “pipes” to configure by hand to get data into the best possible format.
Data that’s actually ready for use
For search, for analysis, for AI, for compliance – no further transformation needed.

