
AI Agents Don’t Have a Model Problem. They Have a Data Problem.
Every major platform at RSAC this year is shipping AI agents for security. Investigation agents, triage agents, hunting agents – and so many promises. Everyone is messaging the same outcomes, let AI do the work.
I agree with the vision. I think the execution is backwards.
Here’s what I’ve been seeing, and a few things I think the industry needs to talk about.
The data is the hard part.
Microsoft’s own State of SOC research makes the case pretty clearly: more than 40% of security alerts go uninvestigated, analysts spend roughly one full day per week on data aggregation (not analysis), and the average SOC team manages eleven consoles. Less than half of an organization’s security data lives in its SIEM.
Those numbers haven’t changed in years, because the underlying problem hasn’t changed. The data is scattered across tools that don’t talk to each other, stored in formats that don’t align, and often sitting in places that nobody queries because they don’t know how.
When you put an AI agent on top of that, you get a faster version of the same problem. The agent queries what it can reach, usually one platform, and reasons about a fraction of the picture. It produces confident, well-structured output. It’s just incomplete.
MCP is not the answer everyone thinks it is.
There’s a lot of excitement right now (and recently more detractors) about Model Context Protocol as the bridge between AI agents and security tools. The idea is compelling: a standard interface that lets agents connect to any data source.
But access and usability are not the same problem. MCP gives you a connection, usually only to a small fraction of the total available data. It doesn’t give you a common data model. It doesn’t resolve the fact that Okta calls a user actor.alternateId, Entra ID calls them userPrincipalName, and CrowdStrike uses something else entirely. It doesn’t normalize timestamps, field structures, or event taxonomies. It doesn’t tell the agent what “HIGH severity” means in the context of your specific environment.
When an AI agent gets inconsistent or limited data, it has to resolve those differences probabilistically — guessing which fields match, inferring relationships, making assumptions about what’s normal. That’s how you get what the research community calls silent hallucinations. The output looks right. It reads well. The reasoning is coherent. But the underlying data conflicts produced a conclusion that doesn’t hold.
Software Analyst Cyber Research recently published data showing that 53% of public MCP servers use static plaintext secrets, only 8.5% implement OAuth, and tool poisoning attacks succeed at a 72.8% rate. MCP is early, and the security model isn’t mature. But even if you solve the security problems, the data quality problem remains. Connecting to a source is not the same as understanding what the source is telling you.
Data will always live in many places. Design for that.
I think there’s a common assumption that the right architecture is one where all security data eventually lands in one place. A SIEM, a data lake, a lakehouse. If we could just get everything into one platform with one schema, the AI problem would be solved.
I don’t think that’s realistic, and I don’t think it needs to be.
Enterprise security environments have data in SIEMs, data lakes, cloud storage buckets, EDR platforms, identity providers, email security tools, vulnerability scanners, ITSM systems, and SaaS applications. Each of those systems stores data in its own format, retains it on its own schedule, and exposes it through its own interface. Some of that data is too expensive to centralize. Some of it shouldn’t be moved for compliance reasons. Some of it is in a data lake you’ve already paid to build.
The faster path to value is making the data you already have, where you already have it, usable for the agents that need to reason against it. That doesn’t mean compliance-driven centralization goes away. It means you make smarter decisions about what to centralize and where, optimizing for simplicity, cost, compliance, or whatever matters most to your organization. The point is that your security team can do their job regardless of where the data lives. It unlocks choice without sacrificing coverage.
That requires broad connectivity, a normalized data model, and semantic context.
Broad connectivity. The agent needs to reach data lakes, SIEMs, cloud storage, endpoint platforms, identity providers, email, threat intelligence, and everything else, without requiring you to always move or replicate data.
A normalized data model. Before the AI touches the data, field names, event structures, and taxonomies need to be consistent. Not “close enough”, but deterministically mapped. The difference between a user called actor.alternateId in one system and userPrincipalName in another can’t be left to the model to figure out at inference time.
Semantic context. The agent needs to understand not just what the data says, but what it means in the context of your environment. What’s a normal authentication pattern. What severity level warrants escalation. What a “resolved” alert disposition means versus a “new” one.
Of these three, context is the one that changes outcomes. Access gets you the data. Normalization makes it consistent. Context is what turns raw events into investigative insight. A service account login is just an event. That same login correlated with DHCP showing it came from a user’s laptop instead of the expected server, cross-referenced with authentication events showing who was on that laptop minutes before and after — that’s how you go from “anomalous login” to “this specific employee used the service account credentials.” That reasoning chain crossed four data sources. No single tool could build it. The mesh doesn’t just give agents access to more data. It gives them the ability to understand what an event means by connecting it to events in other systems. That’s the context that makes AI investigation work. Without it, you have a faster query engine. With it, you have an investigator.
The AI Agent Data Problem
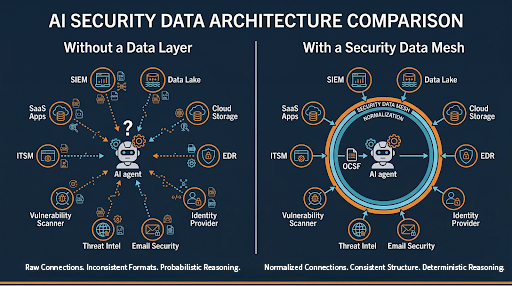
What this looks like in practice.
We’ve been running autonomous agents on the Query Security Data Mesh. We call them Query Workers. A composable AI SOC Analyst, built on skills, frameworks, and gates, that runs on top of the Query Data Mesh.
Investigating a single malware hash ran 24 queries across 10+ connectors (email, EDR, cloud collaboration, threat intelligence) and reconstructed a full kill chain from phishing delivery to endpoint persistence to lateral spread through SharePoint and Teams. 41 compromised hosts. 9 MITRE ATT&CK techniques. None of that was visible in any single tool.
An identity threat assessment swept 8 attack patterns across Okta, Entra ID, and JumpCloud simultaneously, running 39 queries across 6 identity connectors, and found a service account compromised by a specific employee through a four-source reasoning chain: anomalous login, DHCP pivot, device inventory, user correlation. No single identity provider could surface that.
An overnight triage autonomously investigates 120+ alerts across 50+ hosts to 5 confirmed kill chains spanning corporate endpoints and an AWS EC2 instance, finding cross-environment spread that only appeared when all environments were queried through the same mesh.
The AI reasoning was good. What made it work was what the AI reasoned against: consistent, normalized data from every relevant source, queryable through one interface, without moving anything.
The agents aren’t perfect, and they don’t need to be. Every investigation produces a complete evidence package — every query that ran, every source checked, every IOC tracked — so the analyst can verify the reasoning, not trust it on faith. In one investigation, an agent flagged 600+ alerts as an active nation-state intrusion. The evidence artifacts made it straightforward for a human reviewer to identify that the underlying detections had already been resolved as benign. Even when the AI makes a faulty assumption, the analyst still has the data assembled and hours of manual work already done. The real value is in the assembled evidence that makes the human’s judgment call faster and better informed.
The Compounding Value of Connected Sources

We’re not advocating for a specific data architecture.
This is an important point. We’re not saying SIEMs are dead, or that data lakes are the answer, or that you need to rearchitect your security stack. The SIEM-to-data-lake convergence that many are advocating for loudly is a real trend. But whatever architecture you choose, or more likely, whatever combination of architectures you already have, the AI agent still needs to reason across all of it.
Our position is simpler than an architecture prescription: your data will always live in many places and formats. The investment that creates the most value for AI is making that data usable where it already is — not moving it, not standardizing on one platform, but building a layer that normalizes, connects, and provides semantic context across everything you have.
That’s what a Security Data Mesh does. And it’s what makes the difference between an AI agent that queries one tool faster and an AI agent that investigates across your full environment.
The analyst’s job is going to change, too. Not toward replacement — toward focus. Today, most analysts spend the majority of their time as data custodians: pulling logs, normalizing fields, pivoting between consoles, assembling context. The actual security judgment, the part that requires experience, intuition, and knowledge of the business, starts after all of that. We built our entire platform to flip that ratio. The agents handle the data assembly. The analysts focus on the actions that matter: deciding what’s real, what’s urgent, and what to do about it. They’re still the ones defending the company. They just spend more of their time doing it.
Reach Security Data Where It Lives – Or Where You Want It To

The data layer matters, but it’s not sufficient on its own. The agents need structured investigation processes — not just access to more data — or you’re just running chaos at machine speed across a wider surface area. Broad data access, normalized structure, embedded methodology, and human review all have to work together to produce outcomes. Pull any one of them out and the whole thing breaks down.
The AI agent wave in security is coming. The capabilities are impressive and getting better fast. But the teams that will get the most value from it aren’t the ones picking the best model or the most sophisticated agent framework. They’re the ones that solved the data problem first.
The answer isn’t in the model. It’s in the data layer underneath it.
Matt Eberhart is CEO of Query. Connect with him here to see what the above looks like in practice.