
What Splunk Users Tell Us
Splunk users often ask how Query’s Federated Search compares to Splunk’s own Federated Search. The two sound similar, but they’re built for very different purposes. Here’s how to think about when (and how) to use each.
In prospect conversations, I run into Splunk users all the time. The common theme I hear is:
Analysts: “We love Splunk!”
Security Leadership: “We hate the Splunk bill.”
The conversation often continues on to how Query can create the best of both worlds, ie:
- Reduce ingestion into Splunk (or at least avoid putting new data into Splunk) to reduce the bill.
- Expand the reach of Splunk, leaving data at the source (or close to source in any data lake of your choice) and work with it from inside the familiar Splunk Console.
That sounds like magic and that moment usually gets their attention. Excitement and POCs follow once they understand the Query Security Data Mesh architecture that powers our Federated Search capability that is delivered in the SPL pipeline as a Splunk App.
The term Federated Search sometimes leads to confusion in meaning/functionality, compounded by the fact that Splunk has a feature called Federated Search too. After hearing this confusion several times, I figured it’s worth explaining.
Query Federated Search and Splunk Federated Search are very different, aimed at solving different problems. In fact, depending upon your architecture and use-case, it could make sense to use both, next to each other. Let’s dive in!
TL;DR
| Feature |  |
|
| Primary Design Goal | Federate across 50+ data sources | Federate across multiple Splunk instances, Amazon S3 and Security Lake |
| Architecture | Fan-out model across multiple cloud accounts, SaaS, data lakes | Splunk-centric federation across proprietary indexed data |
| Supported Sources | 50+ (CrowdStrike, Okta, Microsoft, AWS, Snowflake, etc.) | 3 (Splunk, Amazon S3, Amazon Security Lake) |
| Extensibility | Rapidly add connectors via Query Connector Framework (1–3 weeks) | 1-year engineering projects with vendor dependency |
| Data Movement | No ingestion or ETL required | Requires data to reside in Splunk, S3, or Security Lake |
| Availability | Splunk App, Standalone UI, API | Splunk Console / SPL |
| Vendor Lock-In | None — platform agnostic | High — tied to Splunk ecosystem |
| Cost | Predictable — agnostic to data volume | Variable — based upon data volume scanned instead of ingested. |
A Quick Look at Each Approach
Query Federated Search
- Federates searches across 50+ common industry data sources that include cloud providers, data lakes, EDR tools, SaaS applications, threat intel sources, IAM and HR systems, Email and network security, and more.
- Ideal for creating a normalized data mesh of your distributed security data that can be searched and used inside of Splunk as needed.
- Architected to be platform / vendor agnostic
- Implemented for third-party data sources (Query does not collect/store data)
- Easy to add support for additional customer data sources
- Available both standalone or as an app in your Splunk Console.
- Relevant for both scenarios – whether you want to continue using Splunk long term, or if you want to use one or more data lakes over time.
Splunk Federated Search
- Federates searches across multiple Splunk instances that large enterprises might have. This serves as a way to search across your Splunk on-prem and Splunk Cloud instance, a common scenario if you are moving from on-prem to cloud, or using both.
- Only available via the Splunk Console and comes with its own pricing model based on the volume of data scanned and available for search (called DSUs – Data Scan Units).
- Originally designed to search across on-prem and cloud Splunk instances. Support for additional sources is limited to Amazon S3 and Amazon Security Lake.
- Support for Snowflake is planned for late 2026.
- Designed to “randomly search something on an infrequent basis”, with a pricing model based on the total volume of data scanned for searching, flipping ingest pricing to scanned pricing.
- See Splunk documentation at About Federated Search for Splunk
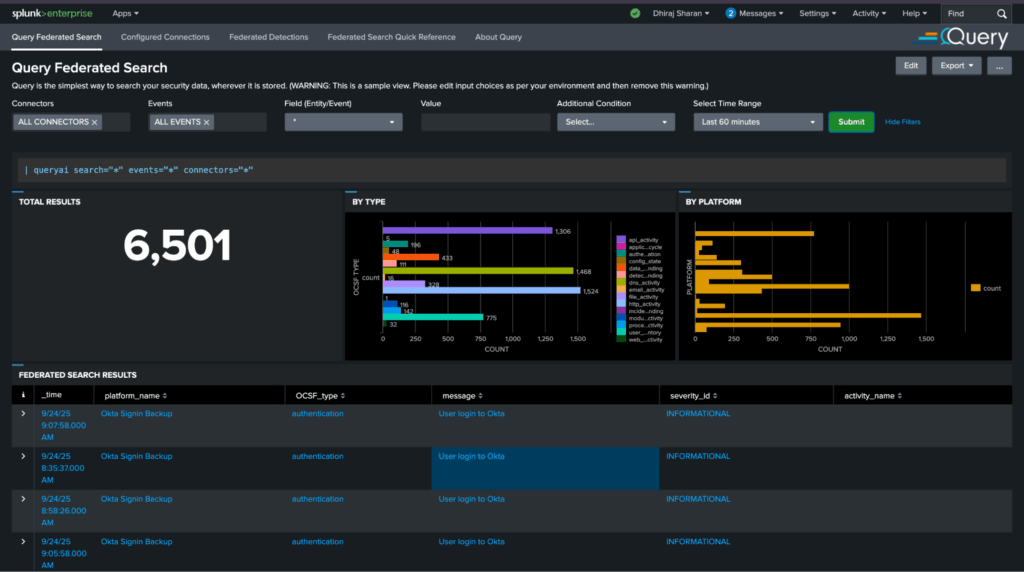
Architectural Differences
Query Federated Search
- Built to execute parallel queries across a large number of third-party data sources.
- Our Query Engine is engineered to fan-out over multiple sources.
- Available as an app in Splunk Console for both Splunk Enterprise and Splunk Cloud users
- Connector Framework makes it easy to extend support to any new data source. (Support for new sources typically takes 1-3 weeks).
- Returns data in one OCSF normalized data set, removing the need to understand and manipulate many different data structures.
- Support for new platforms does not require engineering or product changes by the data source vendor.
Splunk Federated Search
- Originally designed to search across multiple Splunk instances, i.e. it can query only the data that has already been indexed into Splunk.
- Extending federated search to Amazon S3 is available only to Splunk Cloud Platform users with deployments in AWS regions.
- Federated Search for Amazon S3 is not intended for high frequency and real-time searches.
Adding support for new sources requires collaboration and engineering effort from the vendor to implement Splunk’s federated provider interface. (For instance, the recently announced support for Snowflake is in the “design” phase and engineering is “to follow”, meaning yet to start, as per this recent interview. The integration is not expected until July 2026.)
Using Federated Search in the Splunk Console
Query Federated Search
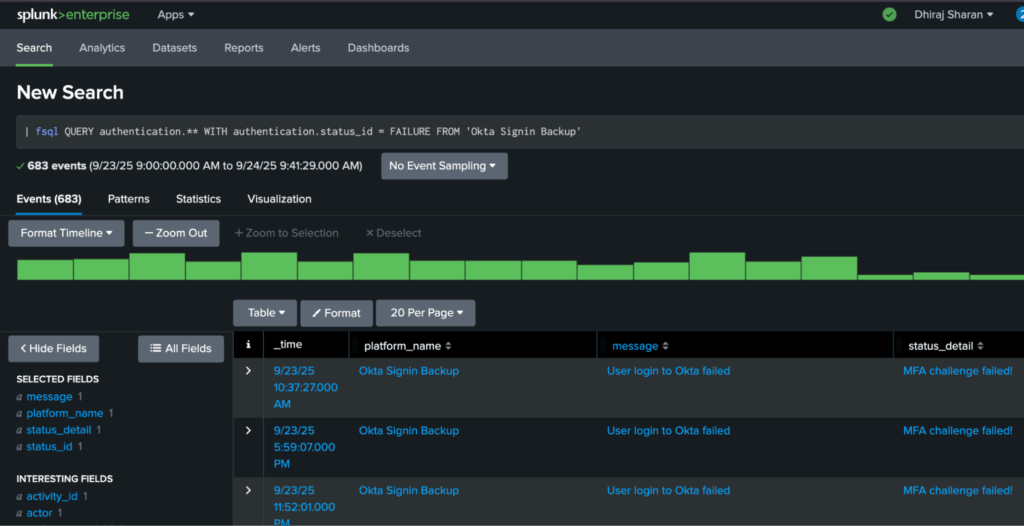
- For users preferring to stay within Splunk Console, Query is available as a Splunk App. It directly extends SPL and makes Query Federated Search available in the search pipeline via | queryai … and | fsql … commands, with results in Splunk Search Console. (For more details on them, see here and here.)
- The app comes with Splunk-native views and users can also create custom views, custom dashboards and federated detections.
- The standalone Query UI is available as an option for customers wanting to take advantage of additional features such as mission-specific AI agents or bridge migration to another SIEM or data lake.
Splunk Federated Search
- Available via SPL in standard mode and | sdselect in transparent mode. For more details, see here and here.
- There is no standalone option – users are locked into Splunk Console.
Cost and Licensing: Predictable vs. Volume-based
Query Federated Search
- Query Licensing is not tied to data volume or usage. It is based on a flat rate per connected data source. This gives customers the ability to plan and project costs, without surprises due to fluctuation in data volumes.
- Query Federated Search is cost effective for everyone, including internally to Query because we are not moving bulk big data out of one platform into another. We are optimizing for executing operations closest to the data source.
Splunk Federated Search
- You have to first pay for the base Splunk platform license. (That is expensive since it is tied to either ingest volume or workload over the data.)
- Next, you need to pay for Splunk Federated Search sold in units of 10 TB (each, a “Data Scan Unit”) for scanning external customer-managed cloud object stores. Overages are billed in units of 1TB, rounded up to the nearest terabyte.
When To Use Which One
Use Query Federated Search
- You have data distributed across multiple sources, cloud accounts, data lakes, and SaaS apps.
- You want to avoid costly central ingestion/duplication, and/or vendor lock-in over your data.
- You have sources that have not been indexed into Splunk/you want to move out of Splunk because of cost. (Common examples I see are EDR data, cloud data, network data, and several others sources that don’t fit well into Splunk.)
- You are using one or more data lakes alongside Splunk and you need a unified way to use all your data, irrespective of whether it is inside/outside Splunk.
- You need fast extensibility to new sources, such as when there is an incident and you don’t want to delay the investigation to wait for the ingestion.
Use Splunk Federated Search
- You want to maintain separate Splunk deployments for organizational reasons, such as an on-prem instance and a separate cloud instance.
- All your data sources are already indexed across the above Splunk instances and their cost is not an issue for you.
Does It Make Sense To Use Both?
In some cases it makes sense to use both, depending upon your deployment architecture and use-case. Use Splunk Federated Search if you have data already indexed in Splunk across separate Splunk instances, and you plan to keep feeding that data into Splunk long-term. Use Query alongside to extend access to data that is not indexed into Splunk and unify visibility in the Splunk console.
I have come across customers who didn’t want to move data out of Splunk, yet didn’t want to add new data to it either. Note that Query is available within Splunk Console as an app, so users don’t have to move out of Splunk UI.
Conclusion
Splunk Federated Search helps unify your existing Splunk instances. Query Federated Search helps you reach everything else — the data that never made it into Splunk. Together, they can give your analysts a complete picture without the complexity or cost of moving data around.
Interested in seeing Query Federated Search inside your Splunk console? Request a demo.