
Introduction
Security teams are building more flexible architectures that prioritize data control, speed, and scale. Snowflake has emerged as a strategic data platform for security use cases, especially when combined with federated capabilities from Query that enable rapid analysis, detections, and investigations directly against Snowflake’s tables and views, without the need for data duplication or re-ingestion.
In this post, you’ll learn why Snowflake is a favored choice among security and SecDataOps teams for both large-scale log storage and targeted enrichment workflows. We’ll walk through different methods to get data into Snowflake using a mix of native services like Snowpipe and custom built tooling.
You’ll learn how the Query Configure Schema and Schema CoPilot make onboarding any Snowflake resource seamless, mapping to the Open Cybersecurity Schema Framework (OCSF) in minutes.
Finally, we’ll look at two real-world reference architectures showing how global SOCs and M&A-driven environments have leveraged Snowflake and Query to streamline operations, improve visibility, and cut costs.
Why Security Teams Use Snowflake
Snowflake is more than just a cloud data warehouse, it’s a fully managed, scalable platform that enables organizations to store, process, and analyze large volumes of structured and semi-structured data. Its decoupled storage and compute model allows for cost-effective scaling, while native support for SQL and robust data sharing features make it a top choice for security teams drowning in telemetry.
Additionally, Snowflake boasts several built-in reporting, visualization, and AI capabilities to further accelerate and enhance security workflows such as security analytics and security business intelligence. From storing logs at petabyte scale to enabling threat detection pipelines and compliance reporting, Snowflake can prove to be an important pillar in the security data architecture of many enterprises. Its flexible ingestion capabilities and native time travel features make it especially appealing for incident response and auditing use cases.
In our experience working with customers who have Snowflake – both as a primary Security Data Operations (SecDataOps) repository and as a “Shadow SIEM” – teams love to use Snowflake both for storing large scale (100s of TBs, or 10s of PBs) logs as well as smaller tables for use in enrichment and contextualization workflows. For instance, teams have ingested EDR and NDR logs into Snowflake tables via S3 Stages for analytics and hunting workflows. Additionally teams write to smaller tables directly (via Pandas DataFrames) to catalog IOCs, vulnerability intelligence, and important asset context data such as LOB and cost center data to identify Crown Jewels and/or ownership attribution.
Getting Security Data Into Snowflake
Loading security data into Snowflake can be achieved through several well-established patterns, with a strong emphasis on flexibility and interoperability. For real-time or near-real-time ingestion, working with a security telemetry partner or using Snowpipe are the preferred solutions. For instance, using Cribl Stream or Monad to move data into Snowflake from a variety of telemetry and firstline tools, such as firewall access logs or EDR tools.
Snowpipe enables automatic ingestion of new files as they arrive in cloud object storage (such as Amazon S3, Azure Blob, or GCS). This allows customers to stage their data in object storage and automatically copy the data into Snowflake, this pattern is broadly known as a “medallion data architecture” where different “metals” are associated with data in various stages of processing, deduplication, and exploitation. For instance, a Bronze layer could be considered the raw streams, the object storage contains normalized data in the Silver layer, and Snowflake becomes the Gold layer.
Snowpipe also integrates seamlessly with event-driven pipelines using platforms like Cribl Stream, Apache Kafka, or AWS Lambda, making it ideal for continuous security telemetry such as firewall logs, EDR events, or identity access records.
For batch workloads, organizations can also use orchestrated pipelines using tools like Apache NiFi, AWS Glue, or Amazon EMR with PySpark, especially when transforming large volumes of semi-structured data into Snowflake’s tabular format. Popular orchestration frameworks like Apache Airflow or Orchestra are also widely adopted to schedule recurring ETL jobs, manage dependencies, and enforce schema contracts before loading.
In our experience, customers tend to prefer using cloud-based object storage – such as Amazon S3 – in a stage and using the COPY INTO command to move larger volumes of data. At Query, we have a security data lakehouse built on Snowflake filled with enrichment and contextual data tables that we automate writing with the Snowflake Python SDK running on AWS CodeBuild, with larger sources of data using Snowpipe.
The flexibility and interoperability with popular tools allow nearly any teams, regardless of their SecDataOps maturity, to onboard data fast into Snowflake and improve their security outcomes. For further reading, consider reading Snowflake’s Best Practices for Security Log Ingestion and Data Normalization in Snowflake guide.
Simplify Searching Snowflake with Query
Query brings simplicity and power to the task of analyzing Snowflake-resident data, without copying or moving it further. The Query Connector for Snowflake is a dynamic schema source, using our no-code Configure Schema workflow you can map any Snowflake dataset into the Query Data Model (based on the Open Cybersecurity Schema Framework).
Additionally, one of our Query CoPilots is dedicated to the task of analyzing your downstream data within the Configure Schema wizard and automatically recommending Event Classes and performing mappings on your behalf. Our ideal target for mapping is under 15 minutes, with the Query CoPilot for Configure Schema we have seen Snowflake data sources onboarded in less than three minutes! You can check me out doing the exact same thing here in a demo video.
Onboarding Snowflake resources (tables, views, materialized views, etc.) involves three straightforward steps:
- Connect to your Snowflake instance via our secure read-only connector.
- Use Configure Schema to define mappings from your Snowflake tables to the Query Data Model. Optionally, have the CoPilot auto-suggest mappings, validate field types, and perform quick mapping.
- Use Query capabilities to:
- Write Detections, complex searches, or data migration scripts with our Federated Search Query Language (FSQL) API and in-console experience.
- Monitor Security Findings with our Investigation Hub.
- Perform IR, Investigations, Threat Hunting, and/or Audits with Federated Search.
- Summarize and draft reports and recommended follow-on actions with our Results CoPilot.
- Accelerate smaller “jobs to be done” with the Query Agents, such as threat intelligence research, vulnerability remediation and prioritization, asset specific searches, or for generating FSQL queries.
Once configured, these Snowflake resources become first-class citizens within Query, enabling cross-platform joins with Federated Joins, Saved Searches, and seamless investigations alongside data from Microsoft, CrowdStrike Falcon, AWS, and nearly 45 more direct Connectors.
Query automatically handles query planning and query execution in parallel across dozens or hundreds of Snowflake Connectors. Instead of executing expensive joins or materializing views, you can collate similar resources with Federated Search, and optionally enrich records in-situ using Federated Joins. In the next section, we will explore some of these same use cases based on customer success stories.
Customer Reference Architectures
Hybrid SOC with Snowflake, S3, and Splunk
A global financial institution we worked with used Snowflake, S3, and Splunk for their hybrid Security Operations Center (SOC) and Security Engineering use cases. Splunk was the main operational Security Information and Event Management (SIEM) used by both IT Operations and Security Operations (SecOps) teams that hosted application logs, network logs, as well as authentication logs across both internal and external identity providers.
Snowflake and S3 were both used for larger low-signal but valuable contextual data sources, namely cloud-based logs across Azure and Amazon Web Services (AWS) Cloud environments. Data was pre-processed and forwarded to Amazon S3 buckets, a majority of which were used as Stages before final ingestion into Snowflake tables. They came to us with the problem that most of their SecOps Analysts and Security Engineers were more comfortable with SPL, and their Detection Engineering efforts were all living within Splunk Enterprise Security.
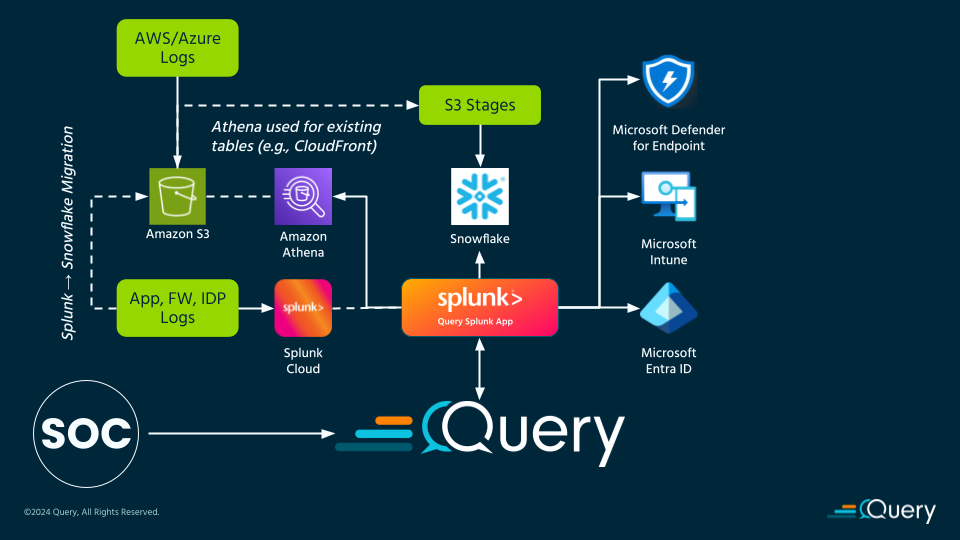
As shown in the reference architecture, Query sits on top, providing unified security capabilities across all platforms and some choice point solutions. Query provided the flexibility to use the right platforms for their strong suits with all Federated Search and Federated Detections carried out via SPL using the Query App for Splunk. Additionally, certain logs that were batched and loaded into Splunk or Snowflake could be offloaded to direct Query Connectors to reduce Splunk costs. Longer term, more and more workloads were offloaded to Snowflake from Splunk while the SecOps Analysts and Security Engineers could continue to use SPL and other Splunk capabilities all powered by the Query Splunk App.
Support Post Merger & Acquisition Tech Stack
It is not uncommon for companies that expand their business via strategic Mergers & Acquisitions (M&A) to have multiple overlapping technologies after the acquisition closes. A lot of variables go into just how integrated companies are, what tech stays behind, what tech is slated for retirement – some of those topics we covered in our blog here. We have worked with companies who have had to maintain multiple versions of the same technologies but from different vendors, such as two identity providers (IdPs) and two firewalls.
Using Query to provide unification of search and detections capabilities, the customer moved their highest volume sources away from their legacy SIEM into Snowflake, while there was some latency added to this network and endpoint data was largely used for contextualization and threat hunting purposes. The core capability of prevention was far more important and led to the greatest security outcomes versus post-hoc detections on the raw signals.
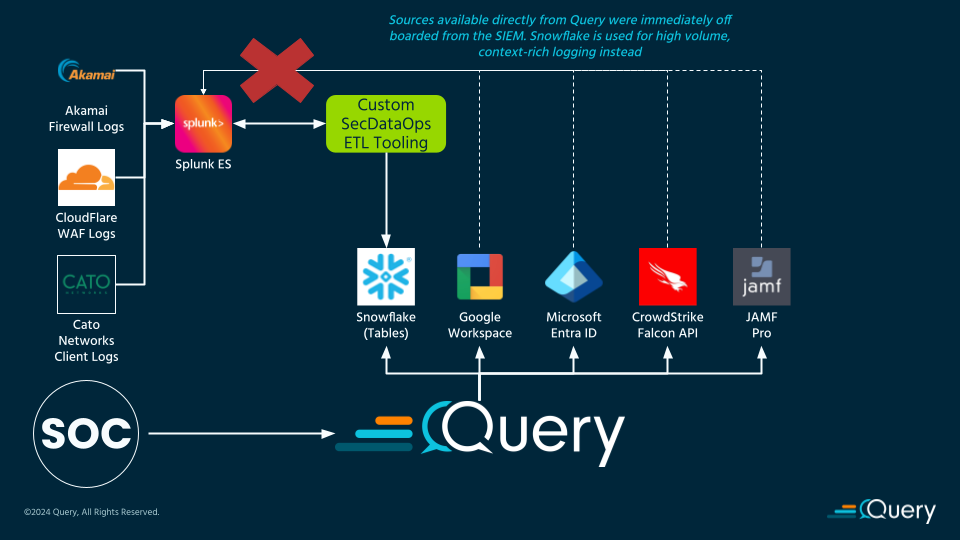
As the architecture demonstrates, custom ETL tooling was used to siphon the data out of the SIEM, normalize, and write into specific Snowflake tables. For sources that have direct Connectors in Query, those Connectors were used instead of sending the data to the SIEM as well to further reduce operational complexity and costs.
Conclusion
Throughout this post, we’ve explored how Snowflake’s scalability and flexibility make it a powerful backbone for security data operations. You learned how to bring data into Snowflake using a blend of native tools like Snowpipe and open-source frameworks, and how Query simplifies access to that data with Federated Search, Schema CoPilot, and dynamic onboarding workflows. We walked through real-world architectures that showed the practical benefits of combining Snowflake and Query across hybrid SOCs and M&A transitions.
If you’re looking to maximize the value of your Snowflake investment and break down the barriers between data silos, Query is the multiplier that unlocks speed, visibility, and control. Ready to bring your federated security strategy to life? Book a demo today and see it in action.