Introduction
A core tenet of the Query Security Data Mesh is providing operators access to data, wherever it lives. Whether the relevant data is behind an EDR API, in Azure Data Explorer, or Snowflake, our Mesh allows you to interact with decentralized and distributed data sources as if they were centralized.
Another tenet of the Mesh is the ability to interact with this data in the ways that makes sense to any security and observability personnel, supporting any number of “jobs to be done”. The most popular way our customers interact with their security and observability data for threat hunting, investigations, red teaming, detection engineering, and many other reasons is via the Query App for Splunk.
Powered by the Mesh, you can interface with any data source Query supports via Splunk without consuming Data Compute Units (DCUs), Splunk Virtual Compute units (SVCs), or ingestion into an Index. For more information on our Splunk App, read more here. Splunk recently announced at Splunk .conf 2025 a long awaited feature for Splunk Federated Search: access to Snowflake. You do not need to wait for the announced July 2026 date to search Snowflake, you can get started today in 60 minutes or less!
In this blog, we will guide you through how to do just that and operate with your Snowflake data directly from Splunk without the additional cost overhead.
Why Federate to Snowflake?
It’s very telling that Splunk decided the next addition to supported sources in their Federated Search solution is Snowflake, and it’s not surprising at all. Both anecdotally and empirically, when it comes to “other data repositories” outside of Security Information and Event Management (SIEM) and Extended Detection & Response (XDR) platforms, Snowflake is the most popular. We’ve already written about that in our blog: Snowflake and Query: Better Together for Security Outcomes.
Without rehashing too much of what we have already written on the topic, Snowflake offers an economically and operationally efficient platform for ingesting, analyzing, and ultimately gleaning insights from true big data. With different types of deployments, warehouse sizes, and public cloud based deployments you can effectively use Snowflake for small, medium, or large workloads. Whether you are just using small Materialized Views to hold enriched CVE data or a deduplicated set of users from Entra ID, or scaling to ingest 100s of TBs of EDR or Firewall telemetry, Snowflake is a popular choice for a reason.
Capabilities aside, the most compelling reason why CISOs and Security Architects are pushing to use platforms such as Snowflake are the economies of scale. Immutable workloads, deduplicated datasets, and tactical enriched datasets do great in traditional databases (OLTP) or analytical databases (OLAP) but are not well suited for SIEMs and XDRs. These are better fit on Snowflake or even a small PostgreSQL database. However, at the same scale, Snowflake will be cheaper than straight up ingest-based Splunk cost models. And if you have properly governed data, properly architected tables and views, and strong SQL skills – you can likely query the data more efficiently than on a SVC-based pricing model.
However, these strong data engineering and governance skills are not something found in a typical security program. That is not due to a lack of care, security teams have way too many jobs within their remit, and the inertia is too hard to overcome to pivot into a completely different field. Remember the tenets we wrote about earlier? Another tenet of the Query Security Data Mesh is that “it just works”. You do not need to become an expert in schemas, in authoring SQL, or remotely connecting to Snowflake: we do that all for you from our Snowflake Connector.
The Mesh isn’t just an architectural pattern, it is a full-service platform that handles meeting your search intent and translating the queries, collating the results, normalizing the data, and providing multiple ways to consume and interact with the data. That plays hand-in-hand with the benefits of Snowflake, you don’t need to agonize over file formats, compression codecs, data types, Crawlers, DDL, or anything else. As long as you can provide the data into Snowflake, we can enable you to effectively search it. And for you Architects and Data Engineers out there: we offer parallelization without expensive JOIN or UNION operations, keeping your Snowflake credit usage on the warehouse smaller.
It doesn’t matter if you have one, one dozen, one hundred, or several hundred tables and views in Snowflake. If there is any relevant security, IT, or observability data you want to use in your security operations runbooks or other security jobs to be done let’s work together today. In the next section, we’ll show you just how easy it is to get started!
Searching Snowflake from Splunk, Today
So you have Splunk, you have Snowflake, and you don’t want to hop between tabs and maintain the same expertise and awareness of SPL and SQL. We can help you increase your speed-to-answer and rightsize both your Splunk and Snowflake deployments and interact with data from both using the Query Security Data Mesh today.
The best place for information on setting up the Query App for Splunk is located in our documentation here. We’ve also written a dedicated blog on the experience called Supercharge Splunk with Query Federated Security, for more high-level information on the benefits. Besides generating API keys and configuring the Query App for Splunk, you’ll need to onboard one or more Snowflake Connectors in your Query tenant as well. Finally, note that you can also configure a proxy server for private Splunk deployments within your DMZ, but we support Splunk Cloud and Splunk Victoria in addition to self-hosted options.
By default, when interacting with data using the Query Security Data Mesh via the Splunk App (or otherwise), we assume you want to search for data across all of your Connectors. Our Query Planner will prune down the sources and craft the downstream queries to meet your intent automatically, if you only wanted to query specific Connectors such as Snowflake or ClickHouse Cloud, you’d need to specify them.
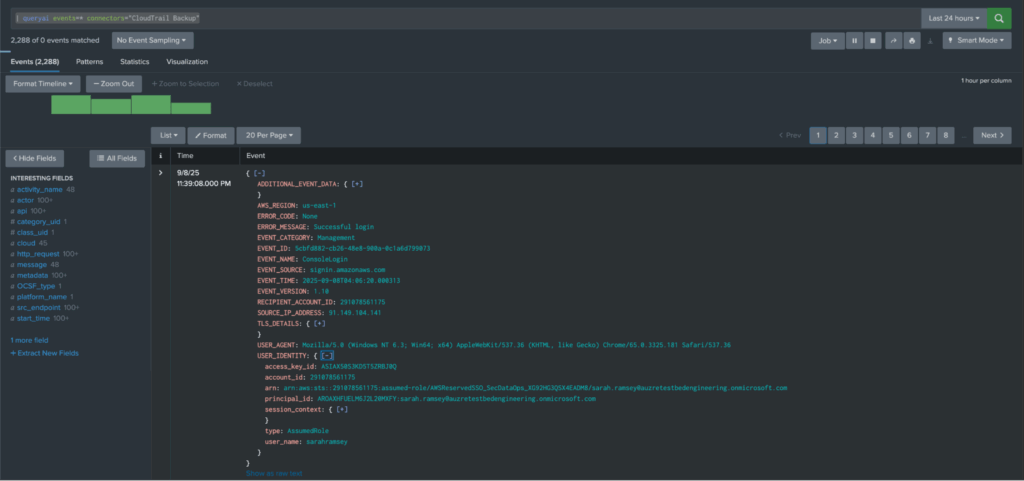
This following SPL query will invoke the Query App to search for any event you have mapped within a specific Connector, in this case, it is a Snowflake View that contains a subset of AWS CloudTrail Management Events – which are a type of cloud audit log from the AWS cloud.
| queryai events=* connectors="CloudTrail Backup"In this mode of operation, you’d get the raw data from the source in addition to the OCSF-formatted data that we provide at search-time within the Mesh, this differs from Connector-to-Connector, but can be very useful to analysts without intimate knowledge of OCSF.
Part of the value proposition of Query is that we provide in-situ normalization of any data into OCSF. For certain types of Connectors, which we call static connectors, such as for EDR or Identity tools; we provide all of the mappings for you. Connected sources such as Snowflake, Splunk (if you were querying across multiple Splunk instances), BigQuery, and Google Chronicle are considered dynamic connectors. You can use our no-code Configure Schema workflow, or use our Mapping Co-Pilot to map your source data into OCSF Event Classes. This mapping of data is what powers our just-in-time normalization.
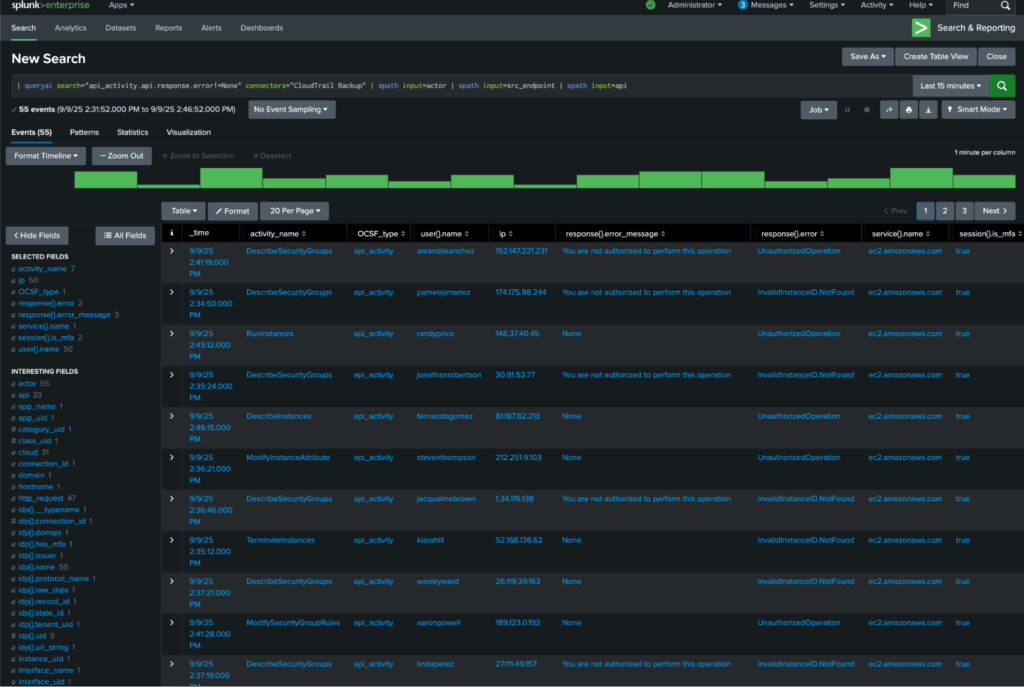
Let’s say you wanted to take advantage of the OCSF normalization, and only wanted to retrieve certain details from the normalized data. Both AWS in their public documentation, as well as our demonstration Connector mapped the CloudTrail Management Event logs to the API Activity event class in OCSF. This query will search for logs where errors were encountered and specifically pull out data on the user (actor), their source network information (src_endpoint), and the actual AWS API activity (api) payloads using spath.
| queryai search="api_activity.api.response.error!=None" connectors="CloudTrail Backup" | spath input=actor | spath input=src_endpoint | spath input=apiFormatting as a table, you’d get results similar to this where you can filter and pivot across as you desire. Likewise, you could take the same SPL and set it up as an alerting rule for detection engineering, or use it as part of a visualization. All of the heavy lifting downstream (query translation, normalization, streaming) is handled by the Mesh.
Where the power of the Mesh comes into its own is using Entity-based searching. Entities are based on OCSF Observables (which are in turn based on Splunk notables) and can represent any IOC or asset identification information in your source data. With dynamic Connectors, you can completely control how you map these.
For instance, some teams want to have a singular entity (such as Resource Name) they search against for all “names” such as serial numbers, hostnames, usernames, and application names. You could also use the direct entities for those such as Serial Number, Hostname, Username, and Resource Name, respectively. It’s up to users how they choose to operationalize around these, but with static connectors we control these for you using the best-fit Entities where it makes the most sense. These mappings are reflected on a case-by-case basis in the Connector documentation.
The SPL query | queryai search="email = 'barbara.salazar@auzretestbedengineering.onmicrosoft.com'" hands the search intent to the Query Planner to find any instance where that email for Barbara Salazar is encountered. For instance, you can expect to get matches across EDR data, authentication data, perhaps pre-processed CloudTrail data, and much more. This brings your analyst correlation-by-collation; instead of jumping from tab to tab and source system to source system, all relevant context on a specific user or device is brought back from all sources connected to the Mesh. Since the data is all normalized already, it makes it much easier to find commonality across disparate sources that would never match by field names.
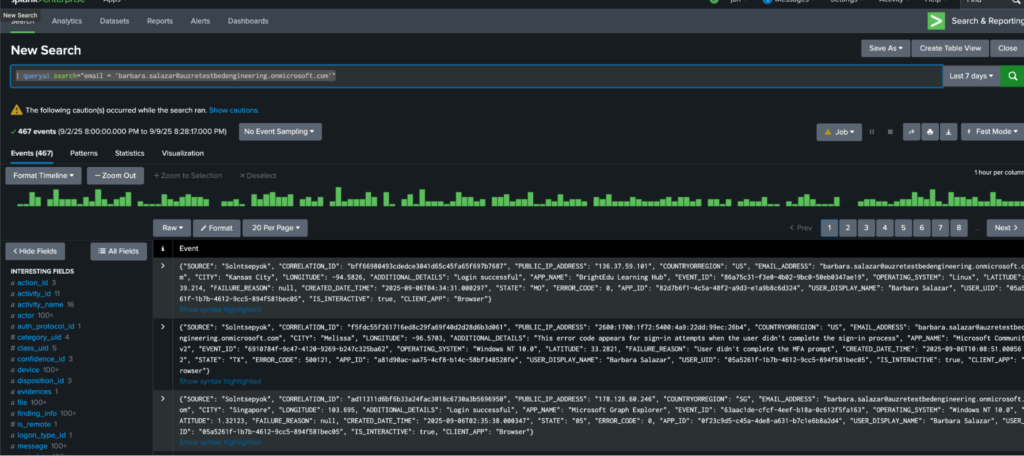
Likewise, this also means less SVCs are consumed having to do fuzzy matching or using regex across indexes. This data is never ingested into Splunk (unless you wanted to), freeing your data to be utilized where it fits best, be it in Snowflake or otherwise.
What will you accomplish using the Query App for Splunk? Will you operationalize data inside of Snowflake, or perhaps migrate key data sources out of Splunk and into Snowflake? Will you use it for detection engineering and/or threat hunting? Will you use our Agents or Co-Pilots to further analyze and make sense of the data using the `| queryllm` SPL command? There is limitless potential for the Query Security Data Mesh in your organization.
Conclusion
With Query, security teams can get the best of both worlds: the power and familiarity of Splunk, paired with the scale and cost-efficiency of Snowflake. Analysts cut time wasted on pivots and data wrangling, while security leaders keep costs predictable and storage flexible. And because the Query Security Data Mesh makes it all work today, without brittle pipelines or long integration projects, you’re not just solving for today’s investigations. You’re laying the foundation for a future where security data is always accessible, always normalized, and always ready to deliver answers.
SecDataOps Savages are standing by, because the Future is Federated.
Stay Dangerous.