
Introduction
AI SOC. Autonomous SOC. LLMs for Security Analysts. You’ve seen it, we’ve seen it, there is something there, but the industry hasn’t nailed it yet. Security lives and dies on data. If your data foundation is weak, no amount of AI will help, and it is beyond a shadow of a doubt that there is a “data problem” across myriad dimensions in security.
Teams cannot get to their data. Teams cannot govern data effectively. Teams cannot store what they want. Teams cannot analyze data. And so on. The latest supposed anodyne is the “AI SOC” which seeks to throw semi-structured JSON across multiple security domains at an LLM and…summarizes it? At least that is what happens when you crowbar away all of the marketing cruft.

Success in modern security operations, and with AI in particular, depends on a simple truth: data is the foundation. The right data, delivered with context and reliability, unlocks speed, precision, and confidence. Without it, even the most sophisticated technology falls short.
This blog is not just an admonishment against throwing 10s of 1000s of tokens worth of JSON-L at Claude or ChatGPT, but also lays out the groundwork for you to build or buy a Security Data Mesh to serve as the linchpin of improving security outcomes with data.
The AI SOC Problem
Let’s all agree that AI shows promise helping humans make better decisions. At least the marketing isn’t lying, it literally is throwing AI models in front of your SOC, and hoping that something good happens. There are plenty of claims about reducing MTTR or addressing more cases per analyst, but what exactly is the mechanism here? More importantly, what do you really need to get to a valuable outcome?
Large Language Models (LLMs) are self-supervised predictors of tokens, trained on a vast corpora of text (and increasingly, multimodal data). They excel at summarization, natural language interaction, and generating structured queries. However, they are constrained by context length, sensitive to prompt quality, and prone to hallucinations. Using them directly on raw security logs tends to produce shallow summaries rather than deep insights, unless carefully constrained with techniques like Retrieval-Augmented Generation (RAG), schema-aware query agents, or domain-specific fine-tuning. Even so, any of those latter technological advances are still garnishing on the main LLM course.
LLMs and Generative AI workflows will gladly take in JSON logs or tickets to tell you about it, when prompted correctly, but this is limited by the amount of tokens a model can accept and the outcome was just a summarization. That hardly moves the needle. Data is the limiter. First, you need the right data, second, you need an LLM coworker that works with you, not against you. And by the way, this problem isn’t limited to LLMs pointed at security operations. AI code editors are arguably one of the more mature (and I’m grading on a curve here) uses of generative AI. Anyone using one regularly knows they can be helpful but they can also run hard in the wrong direction.
The other side of the “AI SOC” is an AI-enabled Security Information and Event Management (SIEM) or Extended Detection & Response (XDR) tool that uses the LLMs to provide access to data. This is typically done by powering Natural Language Query (NLQ) with the LLM, so an analyst can ask “Please give me security logs for the hostname THAT_BAD_HOST?” and the AI workflow will craft a SQL or KQL query, submit it against the right datastore, and summarize the outputs for the analyst. Again, super helpful in theory, but the outcome is dependent on so many data and operational factors.
Modern LLMs can generate code, craft queries, and occasionally invent syntax that doesn’t actually exist. Super! Much like a Roomba dutifully following the “mop my floor” command, they’ll get the job done, but not always by the most efficient path. Sometimes your Roomba decides to eat your cables, batter themselves on your furniture, or get stuck under chairs. The catch is that you’re now paying another vendor to burn tokens against your own data, only to send those results back into their platform, effectively duplicating costs and introducing latency. And remember, people are then making decisions using that output.
This is usually where the marketing slides pivot to buzzwords like Retrieval-Augmented Generation (RAG), Agents, and “Agentic workflows.” In theory, these can constrain models with guardrails, say, a SQL Agent that only emits valid, efficient queries, backed by a vector store of ANSI SQL references and database documentation. You might even get a system prompt so strict it threatens to shut off power if the model dares to write SELECT * FROM my_big_fat_security_warehouse.
Enter the Model Context Protocol (MCP): run it locally or hook into a vendor’s “Superpowered Tools” layer, which promises to keep your LLM on the rails. Just don’t look too closely at the limited functions it exposes or the hardcoded OpenAI API key, technology theater at its finest. Used effectively, like I already said, these tools and techniques can really bolster your AI-enablement but how can you audit the effectiveness of someone else’s SaaS platform? How can these tools be of benefit to your own operating tempo and environment when that sort of specificity isn’t being baked in?

Cynicism aside, AI-enabled workflow in your SOC can be the so-called “game changer” without a doubt. With properly manicured data inputs, sensible Tools in your Agents and MCP Servers, and a good sense to not let the LLM handle every task (like query generation or remediation), you can certainly “supercharge” your SOC with AI, safely. However, that requires a Security Data Operations (SecDataOps) approach to the program. You must work backwards from jobs you need done, from the outcomes you want, and from understanding the capability gaps in AI-enabled systems. You must have properly governed data, ideally standardized and normalized in a way that can be used by LLMs (and Agents), and have touchpoints for humans to be in the loop.
While we cannot solve all the People and Process related challenges, the next Technology answer to this is a Security Data Mesh.
Enter the Mesh
Data Mesh as a concept is relatively young, only being coined in 2019 by Zhamak Dehghani as the long term solution to data monoliths in the Big Data & Analytics space, that issue is not too different from the issues we have in the security space regarding data. Just like in Big Data, a centralized team can quickly become a bottleneck for getting access to insights provided from data, so the paradigm should be flipped to treating data as a product and splitting it into self-service, domain-specific services for consumption and usage by the appropriate teams.
This is easy to think of in security terms, while we can all drive context across subdisciplines there are datasets that typically only make sense for a specific team with a specific job to consume. For instance, AppSec teams will mostly need to consume from SAST, IAST, and DAST with some overlap in AppSec and Threat & Vulnerability Management coming from SCA and traditional CVE or CWE data. Likewise, your Cloud Security team will mostly deal with CSPM or CNAPP data while your Enterprise Identity team will deal with logs from Okta, with some small overlap in CloudTrail logs or CSPM findings about identity constructs.
Everything else in the Mesh that delivers the data for these domains becomes second class, which includes data pipelines which is something of a new obsession for the security industry. While the pipelines, schema registration, query engines, and any other technological choices are important – none are as important as surfacing the right data in the right way to the right teams. The design principles around the data domains include addressable, discoverable, interoperable, and secure data (and some others) but how the data is used is left up to those domain teams.
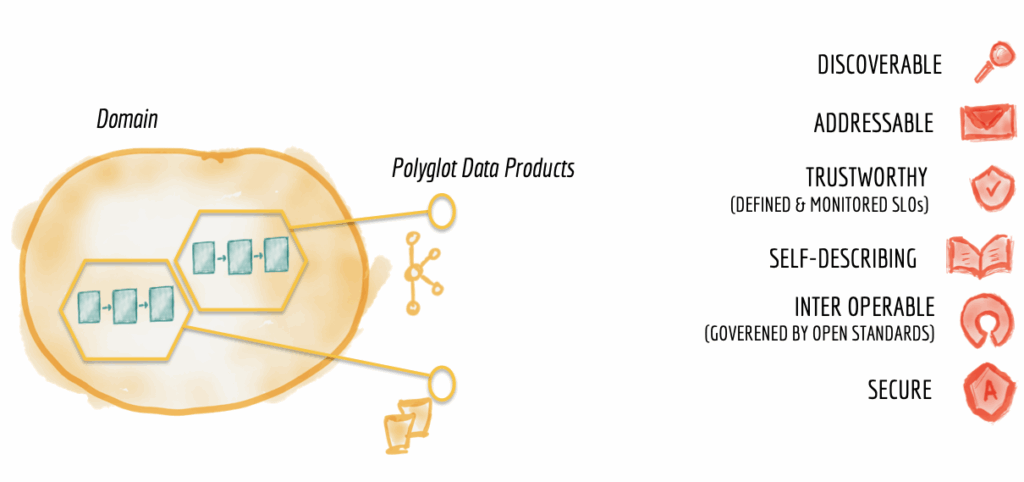
As far as technology goes, you can build a Mesh in a variety of ways, the precursors being the Enterprise Data Warehouses (EDW) as well as the data lake. Since 2019, this space has further developed with the advent of the Data Lakehouse which brings forth some of the more analytical-focused use cases of the EDW (and ACID compliance) via Open Table Formats such as Apache Iceberg and Delta Lake. You can read more about that in a previous article. Any of these technologies can comprise a Mesh as long as you abide by the standards and provide a unified way to get at the domain-specific data that the teams can adapt to.
In fact, you should seek to mix and match technologies if you want to build your own Mesh, or use a tool like Query to enmesh these disparate datastores. Some types of data do better on other platforms. There is a non-trivial amount of considerations to take into account: costs, ease of ingest, ingest speeds, ingest throughput, streaming or batching, medallion architectures, data temperature (hot, cold, warm), regulatory compliance for storage, archive strategy, recovery, and way more.
Again, we cannot answer that all for you, as everyone has different requirements but some datasets make more sense in one repository than another. Immutable security incidents sent from your EDR should likely stay there, medium-volume IAM-related logs make sense in a warehouse, where extremely high-volume firewall logs probably make more sense in a SIEM – or you can trade latency for efficiency and preprocess them before landing into a data lake. The point is, security data is going to be in many places and that’s actually a good thing. You need to plan for it and have capabilities for the right teams to use the data they need.
The Mesh as a distinct technology solution is something that is new, and what we have built (and keep building) at Query. We are quite literally the industry’s first Security Data Mesh in which solutions such as Federated Search and Security Data Pipelines are built on, as well as our mission-specific Agents and CoPilots for summarization and data modeling tasks. Talk is cheap, how do we do it?
Security Data Mesh Done Right
While I would love to provide you Dirty Deeds, Done Dirt Cheap, our legal team has forbidden me so instead we provide Security Data Mesh, Done Right. As mentioned in the previous section, Data Meshes are typically technology agnostic and I do not think Zhamak intended her idea to be a product category at all. However, security teams are not data teams, and just want to get answers from their data no matter where it lives.
As much as Big Data & Analytics has changed, so too has security. In the field, we often run into teams that have at least three different data repositories (SIEMs, lakes, APMs, warehouses) if not dozens more. Long gone are the days of ElasticSearch (ELK) and Splunk being the dominant security data repositories, now teams are more willing to experiment with new technologies and decouple themselves from the tyranny of SIEM billing. However, this does cause operational issues, which is further complicated with your EDR or Identity tools also becoming data repositories. You have Crowdstrike LogScale, Microsoft Sentinel, SentinelOne Singularity Lake (or XDR?), and many others wanting to take your data.
At Query, we don’t care where the data is. The key principle of the Data Mesh is exposing the right data to the right people, in the right way. At the heart of the Query Security Data Mesh lies several patented technologies that build our Query Engine. Query Engine is a metastore, a planner, an execution engine, an in-situ normalization tool, and serves as the nexus for serving up distributed data in a centralized way.
Unlike the Data Fabric concept, which seeks to “weave” or “stitch” data together in a Fabric, not too unlike a SIEM or an XDR: we never store or duplicate data. While this just-in-time serving of data does increase latency to be no faster than the downstream APIs, it is orders of magnitude faster than the alternative.
In-situ normalization completely removes the necessity of having security data pipelines everywhere, yet another principle of a Data Mesh we follow. Pipelines, ETL, and other transformations are a second-class citizen in the Mesh and something that should be totally opaque. When you search for an indicator, an entity, an asset, or a specific cluster of domain-specific data (vulnerabilities, authentication, patch data, etc.) we handle all of the normalization and standardization for you. Your teams want answers to their questions: for context, for enrichment, for correlation, for closure. We give it to you at human speed.
Besides being cool to say, in-situ normalization serves AI-readiness incredibly well. Backing all of the data into the Open Cybersecurity Schema Format (OCSF) provides commonality and interoperability of data points that is key for machines. Whether it is powering Analytics, Business Intelligence (BI), or being provided to machine learning models or AI workflows, standardized data is much easier to understand. Instead of having IP Address or Hostname called 7 different things by 5 different tools, commonality is the main watchword of OCSF, which makes it easier for analysts to understand what they are looking at regardless of where the data is coming from. Remember, we want to expose domains of data not individual raw data points, it’s all about clarity and speed-to-answer not just orchestrated queries.
This is where our Federated Search solution is differentiated from others. Splunk Federated Search only supports S3 and requires you to use a new command line syntax, a specific version of Splunk Cloud, and still ingests these downstream AWS Glue tables (which are pointers to schemas in Amazon S3) as “federated indexes”. If you are already building a data lake on S3, why would you pay extra money to use it in an inefficient way in antiquated technology? A better approach would be to use our Splunk App, which gives you access to our 50+ integrations all within Splunk, with a simpler SPL syntax and without ever ingesting data into an index or consuming compute credits.
Other Federated Search solutions are lacking just as much. Either being a thin shim around transpiled SQL queries sent from a data platform (like Databricks) downstream (to PostgreSQL or otherwise), or they’re like Cribl Search which uses KQL to query data in Cribl Lake but does not allow you to parallelize the queries across multiple sources and union the data without incurring several expensive operations. Query essentially offers a UNION on data by default, we correlate-by-collation, all of our data is returned in OCSF format combining different data domains by shared characteristics.
We are working side-by-side with you to unlock the promise of AI SOC. Our CoPilots and Agents were built after watching the industry set the promise of AI on fire for over a year. We only came to market at the right time when we were confident that we could fine-tune models, provide the right context via RAG and Agentic workflows, and actually provide capabilities that made sense to teams. Our CoPilots can analyze several 100 event classes at a time of OCSF data, allowing you to summarize data in a meaningful way that is carefully curated for the LLM to have the most accuracy in analysis, improving your outcomes.
Our CoPilots are also experts at data modeling into OCSF. We get it, OCSF is hard to learn and harder to operationalize. We want that to be opaque to you, so our CoPilots can analyze nearly any security or observability dataset and pick the right OCSF event class and minimum necessary mapping for you to draw insights from and search at any time. Furthermore, our Agents are aligned to specific data domains: Threat Research, Vulnerability Management, Triage, Asset Management, and otherwise. They understand how to use our Query Language that can traverse the mesh effectively to expose the insights that matter to you.
If you want to power security analytics, BI, extract features for your own MLOps, fine tune your own LLM models, or power your own Agents: use our Query Language. Federated Search Query Language (FSQL) is a syntactically familiar query language that provides even more powerful capabilities than our own UI or Splunk App. For instance, you can search across categories of OCSF event classes – essentially search several Domains of data at once – you can search disparate events at the same time, search for specific attributes, or search for several entities at the same time. Don’t remember if it was a Resource Name or a Hostname that references an asset class? Easy game. Don’t remember if Crowdstrike mapped their FDR process data to Module Activity or Process Activity? All of these use cases are provided by FSQL.
Conclusion
Some marketers want you to believe that the future of security is duct-taping an LLM to your logs and calling it intelligence. These folks fancy themselves gunslingers, blasting buzzwords like “autonomous SOC” and “Agentic workflows” while quietly billing you to query your own data with models they don’t control and platforms you don’t trust. It looks exciting on the demo stage, but it collapses the moment you need depth, scale, or reliability.
And here’s the painful truth: many security teams reach for these shortcuts because the underlying problems are real. Data is fragmented. Pipelines are brittle. SIEM bills are predatory. Analysts are drowning in noise while leaders demand “AI” as a silver bullet. The temptation to grab the shiny tool is understandable, but it won’t fix the foundational issues.
That’s why the right path forward starts with solving your data problems in a way that will scale. It’s a Security Data Mesh. Governed, normalized, and domain-aware data that gets the right context to the right teams, at the right time. When you own that foundation, you can layer AI where it actually adds value; summarization, enrichment, triage. All without handing your budget (and your data) to someone else’s marketing department.
Stop subsidizing rented AI wrappers. Start investing in infrastructure that puts you back in control of your data. Query’s Security Data Mesh was built for this exact moment, bringing access to the right data from the right places in the right way at the right time. If you want AI to matter in security, first get the data right. Then let’s build on it together. Come be a data mesh gunslinger with us.
SecDataOps Savages are standing by, because the Future is Federated.
Stay Dangerous.