
The Query AI Origin Story
Today, the Query platform is synonymous with Federated Search, but why and how did we get here? Being the founder, let me take you through my journey to Query. The early stage startup journey involves understanding market problems and delivering innovative, game-changing solutions.
My cybersecurity career began in 2001 at ArcSight, right around its founding. Over the next 12 years, I and my amazing colleagues built ArcSight’s category-creating SIEM product from the ground up. Through the lens of that SIEM, log collection and analytics experience, I saw the coming growth and challenges with security data. It looked to me that in the coming years with the advent of cloud and SaaS, SIEMs would fall apart with the data explosion and analytics complexities. See my previous blog here where I go deeper on learnings from my SIEM journey. Fast forward to today, organizations still find it extremely hard to reach their own data and get answers out of it.
One major stop in my SIEM / security analytics journey was building Niara’s User and Entity Behavior Analytics (UEBA). That exposed me to the AI and ML world, where we used neural networks to understand user behavior and intent, detect anomalies, and model and quantify risks and threats. For more on Niara’s Deep Learning, see this tech talk from 2017 Spark Summit Deep Learning in Security—An Empirical Example in User and Entity Behavior Analytics UEBA. Post Niara, I was ready to use AI to make better sense of distributed log data.
I started Query.ai as an AI company. I knew we would need AI and NLP breakthroughs to understand heterogeneous and often unstructured/semi-structured data lying in remote locations – the type of data that is typically not ingested into SIEMs but is very relevant during any investigation. Examples would be S3 or other cloud repos, identity and HR information, and so on.
During the early research and prototyping phase of Query.ai, I created a conversational AI bot using NLP (Natural Language Processing) and named it IRIS (Investigations Response Intelligence Service). The prototype’s browser based interface was somewhat similar to ChatGPT – you would ask your data questions in plain english, and it would run queries to bring you answers from your remote data. The browser app even had a voice interface where you could literally have a voice conversation with IRIS (did you notice that Iris is Siri spelled in reverse 🙂). IRIS’s technology was based on BERT (Bidirectional Encoder Representations from Transformers), a precursor to today’s transformer based generative-AI models. Unfortunately, we were seeing more than our acceptable level of inaccuracies in IRIS’s intent detection, which made it difficult to productize it, especially as a solution for mission critical investigative searches run by cybersecurity analysts. We did get academic success in creating that intellectual property, with patents granted. Our approach to connect to remote data sources to run the user’s query live was also really well received. We continued on that path to connecting to multiple remote data sources, querying them in parallel, and bringing results to the analyst in a meaningful fashion. Federated Search was born!
Above progress brought great support and funding, along with the building out of our stellar team led by our CEO Matt Eberhart. We garnered recognitions along the way – Gartner Cool Vendor, SINET 16, and a strategic investment by Cisco’s AI investment fund.
The Evolution with LLM
While we were hands down productizing federated search, the question that was often asked to me was “When are you productizing your AI?”
Today, we have a strong federated search solution. And also LLMs are here. So now is that time!
IRIS’s AI and NLP origin has now evolved further and is based on LLMs. The recent generative-AI advancements with transformer architecture have provided breakthroughs that enabled IRIS to understand the user’s intent much better than earlier, and produce very directed contextual answers.
Today, I am glad that that day has come that IRIS is getting reincarnated into what we now simply call ‘Query Copilot’.
The Query Copilot – get answers from your distributed security data
Analysts are not always experts in individual data sources. Each data source has its own idiosyncrasies. There is often more useful information in the unstructured log than what is sent to, or even recognized by SIEMs. Multiply that complexity by the 15-50 data sources that large organizations have in their distributed environment, you would know it quickly gets impractical for analysts, whether they consume that data via SIEMs or via the 15 browser console tabs. AI is needed to help understand and make sense of that data.
That’s where Query Copilot comes in! It helps answer questions from your data. It can give you recommendations based upon both your local context, and its global threat intelligence context. It also helps deal with new data sources – for example, it can map data from raw formats into a security schema (OCSF in our case).
The Copilot sits on top of federated search, i.e. centrally across heterogeneous data in multiple decentralized platforms. That gives our LLM the ability to reach distributed data. The LLM stays private to a customer tenant. The data goes through our LLM only if the user chooses to do so, and the user can also filter what subset of data should be visible to the LLM.
It took time but we have come a long way. For the technical minded, here is some further look back on our early work from the pre-LLM days. IRIS’s original models were for NLU (Natural Language Understanding) and NLG (Natural Language Generation). It (or she!) extracted the user’s intent and relevant parameters using intent and entity classification. Its early building blocks were:
- Dialogflow, which was Google’s platform for developing chatbots, voice bots, and virtual agents. In 2020, our stack was built using Google AI and NLU. (Side note: Their newer Dialogflox CX agent is now based upon Gemini’s gen-AI model.)
- Rasa, an open source machine learning framework that automates text and voice-based conversations. In 2021, our team embedded Rasa in our cloud and we also contributed back to Rasa’s open-source.
- BERT (Bidirectional Encoder Representations from Transformers), the NLU deep learning model that utilizes the Transformer architecture, and has some commonality with GPTs of today (though it doesn’t do generation and is primarily for NLU). BERT was introduced by Google in 2018. We researched creating word vectors from the user sentence and then taking it through BERT for sequence labeling and text classification. The bidirectional encoding allows the predicted word to “see” itself conditioning each word on its previous and next words.
- Our iterations also used Python machine learning and NLP toolkits like Nltk, Pattern, and scikit-learn.
If you want to read further from those early days, here are some of our technical blogs over AI, NLP, and machine learning:
- What is Natural Language Processing? A Beginners Guide
- Basics of Applied Natural Language Processing
- Natural Language Processing Dictionary – Query
- Looking further into Machine Learning using Python
Copilot Examples
Not only can Query Copilot summarize search results, it can also answer follow-up questions from the federated search data. This becomes very useful for scenarios related to providing recommendations, suggesting follow-up actions, helping find the needles in a haystack, and more.
Below are some early examples. Our product team will share more details and content as we roll out capabilities.
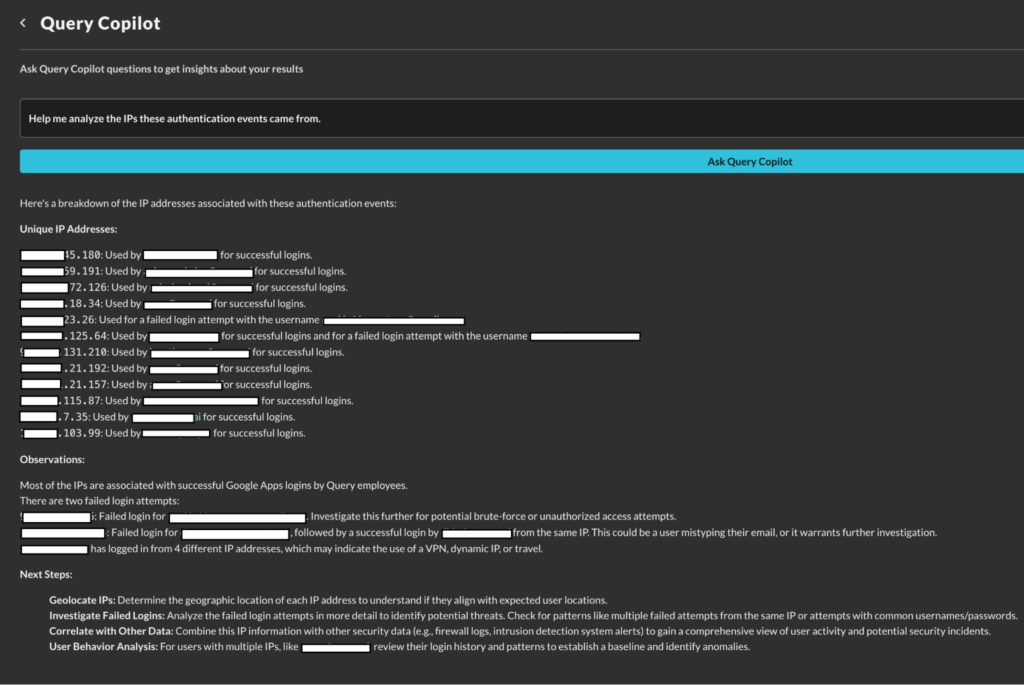
Query Copilot analyzing authentication events, finding suspicious ones, and recommending followup:
Query Copilot suggesting follow-up action in Splunk Search UI:

Query Copilot is in beta. To give it a try, reach out to us here.