
Recently we gathered for a company all-hands in New Orleans. Since that event included a lot of recent hires, I shared the Query founding story with the team. It was a good time to look back, reflect, and discuss why we do what we do. That session with the team made me think, “why not capture and share my founding story more broadly via a blog?” So, here it is!
My SIEM days of Iterations and Evolution
I was fortunate enough to be in the right place at the right time to build/ride the last 20+ years of the SIEM and security-analytics wave. My journey with cybersecurity and SIEM started in 2001 when I joined an early-stage, pre-product startup named ArcSight. Working as a developer implementing early ideas from our Founder/CTO, we released the first SIEM that became wildly successful over the years.
The Cybersecurity Big Data Growth Pains
In my 12 years at ArcSight, I lived the data growth pain while leading our server and database teams. You may not believe today that we stored security event data in Oracle in our initial releases. We would work with customers’ DBAs, managing their shared production Oracle instances. Soon we outgrew and asked for bigger servers, more CPUs, more RAM, and a bigger Oracle cluster to try to scale to the data volume.
It became clear that relational OLTP databases were not the answer to storing ever-growing and ever-so-heterogeneous security data, and the industry needed a NoSQL solution for faster insertion and querying of time-series log-data. A mix of proprietary and open-source platforms cropped up in the industry, but I will just name a few here:
- At ArcSight we came up with a columnar and partitioned storage NoSQL engine called CORRE (which means to run fast in Spanish). Post HP acquisition, Vertica was also used later as an analytics data store.
- Of course, Splunk came along and ate everyone’s lunch with its proprietary NoSQL engine and clustering built for easy and faster log storage and search.
- Elasticsearch grew in the open-source world from the Apache Lucene key-value inverted index and became the underlying platform for many SIEM and log management vendors.
With the advent of cloud storage, another set of data and analytics platforms were built on top of cheap cloud storage:
- Snowflake, which changed the pricing paradigm from volume/storage size to query cost.
- Amazon Security Lake, which leverages the Parquet columnar compression over partitioned and normalized (in OCSF format) security data stored in S3.
These current solutions operate under the assumption that all security data can be centralized, but talking to CISOs and their teams, we rarely find environments that have successfully centralized all their security data into a single platform.
My days of Getting Answers from Security Data (a.k.a Security Analytics)
Ideally, security analysts should not have to deal with the technological complexities of a storage and search platform. Whatever can give them fast answers from their searching/querying is really all that should matter. However, cybersecurity data is almost the biggest and the worst offender in terms of the 3 V’s of big data – Volume, Variety, and Velocity. Hence, analysts and cybersecurity tech vendors alike are unintentionally sucked into compromising for cost and scale when it comes to getting meaningful analytics out of cybersecurity data.
After ArcSight as well, I continued to face the above challenge first-hand in the cybersecurity companies I became part of. At different times, I was developing Hadoop-based security big-data lake, entity correlation/detection, user and entity behavior analytics (UEBA), and network traffic analysis (NTA) solutions, and all had limitations or made compromises because of the enormity and variety of cybersecurity data.
Current State of SIEM and the elusive Security Data Lake
The state of despair with security data and the limited success with correlation has almost made SIEM a dirty word. The industry found more actionable results with curated EDR alerts than alerts from the SIEM correlation rules. Hence the recent marketing push to reinvent vendor-hosted SIEM as XDR, in my opinion! The volume has grown so insane with terabytes of data that the industry has abandoned the belief that SIEM should hold all security data. Rather, it has been reduced or redefined to only get alerts from the data sources or intermediaries without the raw data details. The purpose is centralized alert-triage interface vs. a true security data lake. This does mean that the analyst has to do swivel chair analytics going back and forth between different products. See Eric Parker’s blog on Why So Many Tabs.
The security data lake is also being attempted outside of SIEM for both cost and performance reasons. So far these are home-grown attempts where the CISO’s team hires platform engineers and developers to build on one cloud stack vs. taking an off-the-shelf vendor solution. This is an expensive and time-consuming route, and success is limited to only a few at the very top who can afford to build.
We live in a Decentralized Security Data World
In the past 5 years, another set of problems have hit the industry; cybersecurity data has suddenly become even more decentralized with the move to cloud and the success of SaaS. During Covid times, organizations were forced to adopt a zero-trust architecture, as traditional network boundaries were gone. CISOs faced the helplessness; the lack of visibility and control, and the inability to monitor employees working from home as they accessed company data over vendors’ SaaS over the internet.
Maybe it is time to accept the reality that cybersecurity data is big and everywhere. Analysts getting easy access to that data irrespective of what third-party vendors are holding it should be the thought process instead of. fighting to move and centralize it all of the time.
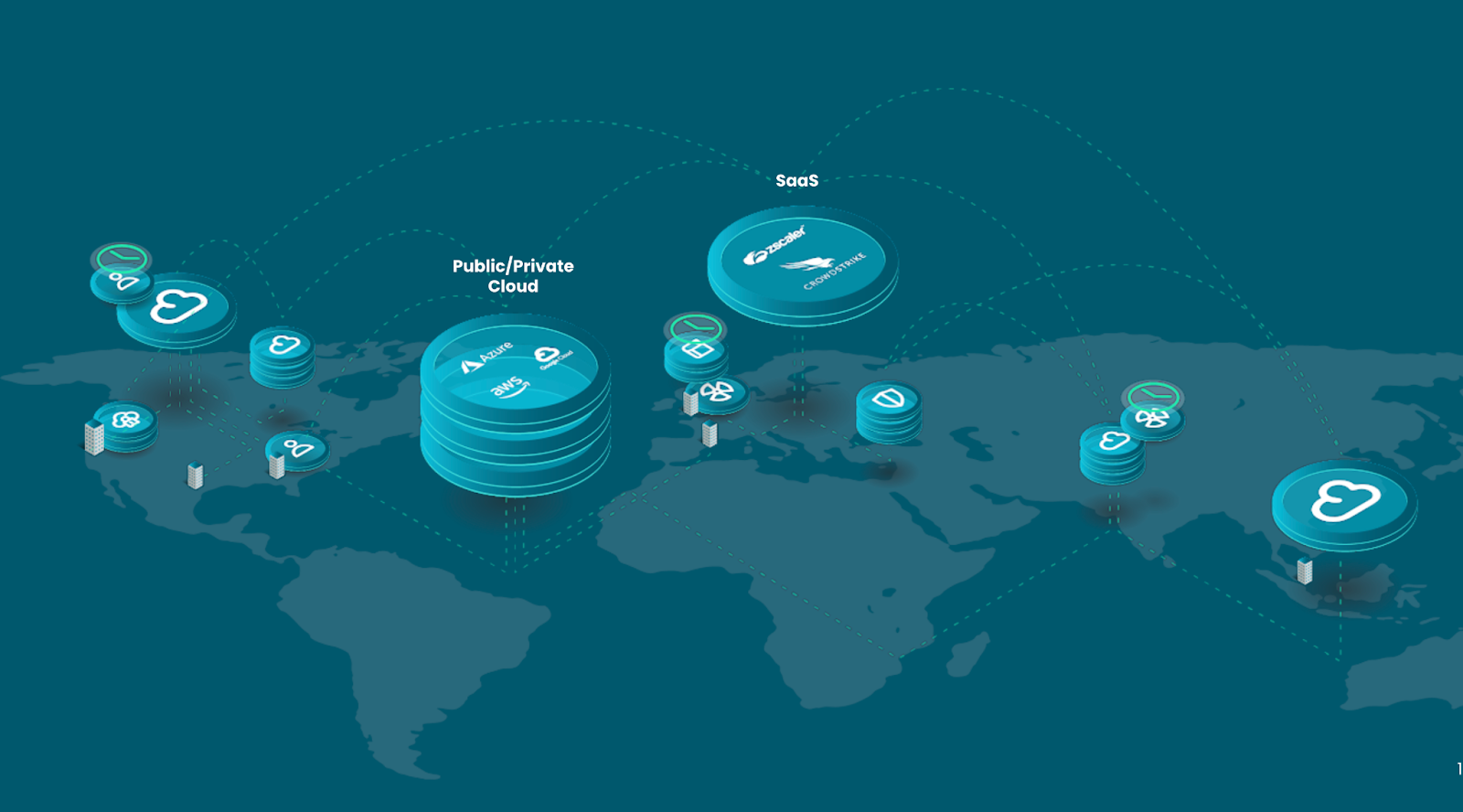
This realization was my startup story to Query!
The Query Journey starts with Federated Search
Once you reach a stage where you are ready to accept and willing to live in the decentralized cybersecurity data world, then you start looking for solutions with that mindset . That was the mental shift I had to go through, and that is how we arrived at Query’s Federated Search where you ask questions about your data and get answers from everywhere your data lives.
Building with that approach, Federated Search has been eye-opening as it brings search to where the data lives vs. moving data to your search platform.
Vendors are opening their platforms via APIs
Cybersecurity has to be open and collaborative, as no single vendor can provide a complete solution that doesn’t require any integration with the tools present in the customer environment.
Five years back, it would have been extremely difficult to think of a Federated Search solution and build it successfully because vendors’ APIs were limited. They are still limited in many cases, but the industry is shifting quickly and vendors are on a scramble to make their platforms accessible via APIs. They risk losing relevance and becoming legacy if they don’t move fast to become part of a collaborative cybersecurity ecosystem.
And finally, there is broadening vendor support for the open-source cybersecurity industry data-model, called OCSF, so that vendors can produce and consume each others’ data in a common schema. Refer to my prior blog on OCSF here to learn more about it.
The Query journey beyond in the decentralized world
While Federated Search is the first step after the above acknowledgement of our decentralized environment, it is not the full solution. It is rather the start of the journey into a decentralized world where with some out-of-box mindset, one can apply innovative solutions for traditional SIEM-domain problems of cybersecurity analytics, reporting, correlation, investigation, and remediation. The industry has become conditioned into thinking that we need to centralize data first to solve these problems. At Query we are taking a fresh look at how to solve these problems in the decentralized cybersecurity data world.
I would love to hear your thoughts on Query’s journey into decentralized data. We can benefit from learning your experiences around cybersecurity data and analytics problems. Please reach out to me or contact Query (contact@query.ai) if you would like to discuss any of the above further.