Introduction
Security teams generate and consume vast amounts of data from firewalls, endpoint detection and response (EDR) systems, intrusion detection systems (IDS), and other security telemetry sources. Traditional SIEMs and log management tools often struggle with scalability, cost, and performance when handling these high-velocity logs. Open lakehouse architectures offer a flexible, cost-efficient alternative, and Delta Lake can be a great choice for implementing this model.
In this blog you will learn about the basics of the Delta Lake table format and its applicability to Security Operations (SecOps) and Security Data Operations (SecDataOps) teams. You will get hands-on by creating a Delta Lake table on Amazon S3 using the Delta Lake Python SDK with synthetic security data. Finally, you will learn how to query the data using DuckDB with some basic SQL.
Delta Lake 101
Delta Lake is an open-source storage layer, known as an open table format, that improves data lakes by adding ACID transactions, versioning, and schema enforcement on top of cloud object stores like AWS S3, Azure Data Lake, and Google Cloud Storage, not to mention Databricks! It achieves reliability through a transaction log (_delta_log), which tracks all changes, ensuring consistency, rollback capabilities, and schema integrity.
Built on Apache Parquet, Delta Lake differs from other open table formats like Iceberg and Hudi by not requiring an external catalog. Instead, it embeds all metadata and versioning within the transaction log, allowing compute engines to interact with the data without a centralized metastore. This design makes Delta Lake portable, scalable, and easy to integrate into existing data pipelines without additional infrastructure–notably a metastore or data catalog.
The Delta Lake ecosystem provides multiple ways to write and read data. The Delta Lake Python SDK (delta-rs) allows direct programmatic access for app developers, while PySpark and Flink provide scalable batch and streaming ingestion, respectively. On the query side, Delta tables can be read using DuckDB, Amazon Athena, and Trino, enabling SQL-based analytics without requiring a Spark cluster. These integrations make Delta Lake a versatile option for handling large-scale, structured data efficiently.
For more advanced use cases, Delta UniForm allows seamless interoperability with other table formats like Apache Iceberg and Hudi, making Delta more flexible in multi-format environments. Delta Sharing enables secure, open data sharing across different platforms without copying data, supporting cross-organization analytics while maintaining access controls.
Delta Lake and SecOps
For the SecOps team or wider SecDataOps program within a security organization looking to experiment or expand a data lakehouse, Delta Lake makes a lot of sense. From a pure utility perspective, given the fact that an external catalog is not required, it’s the fastest way to start with an open table format for an open lakehouse project. However, there are more benefits to it than the simple fact that the _delta_log ensures ACID compliance and cataloging.
One of the biggest advantages for security teams is Delta Lake’s ability to handle high-velocity security log ingestion at scale while keeping data queryable in near real-time. Traditional SIEMs and log management platforms often struggle with cost and performance when handling terabytes of data per day. By storing logs in an open lakehouse format with Delta, teams can decouple storage from compute, retaining full-fidelity logs without vendor lock-in while running ad hoc analytics or detections on demand. Queries can be optimized with partitioning and caching, reducing the time needed to investigate threats.
Additionally, Delta Lake provides a more flexible foundation for detection engineering. Security teams can iterate on detection logic using SQL or Python without waiting on a proprietary SIEM’s indexing process. With Delta’s ability to support both batch and streaming workloads, analysts can test new correlation rules across historical and live data seamlessly. This agility helps teams pivot quickly in response to evolving threats while maintaining cost efficiency compared to ingest-based SIEM pricing models.
Delta Lake is built to handle substantial throughput, with some deployments ingesting hundreds of terabytes of data per day, scaling to gigabytes per second in environments optimized for performance. However, actual ingestion speed depends on infrastructure, data architecture, and processing strategy. With proper SecDataOps governance, leveraging optimized partitioning, streaming ingestion, and compute scaling security teams can process high-volume logs from firewalls, proxies, EDRs, and other sources in near real-time. This ensures faster investigations, threat correlation, and efficient long-term log retention without the storage and compute constraints of traditional SIEM solutions.
In the next section, you will learn how to get started with Delta Lake right away by creating your Delta Lakehouse atop Amazon S3 object storage.
Building with Delta Lake on Amazon S3
In this section, you will learn how to create a proof of concept for data stored in Delta Lake atop Amazon S3. You could replicate these steps on other object storage data sources, but that is out of scope for this blog.
If you prefer to run the code on your own, you can download it from our GitHub repository here. Be sure to modify the values for S3_BUCKET_NAME, S3_DELTA_PATH, and S3_BUCKET_LOCATION.
Prerequisites
Some of these prerequisites are for the next section, Querying Delta Lake with DuckDB.
- Have access to an AWS Account with Administrator permissions, or at least
s3:CreateBucket,s3:PutObject,s3:PutObjectAcl,s3:GetObject,s3:GetObjectAcl,s3:GetBucketLocation, ands3:ListBucketAWS IAM permissions. - Have AWS credentials configured, either using the
aws configurecommand, AWS IAM Roles Anywhere, or other mechanisms. - Have an existing S3 bucket, or the ability to create one to store the data in Delta Lake.
- Have at least Python 3.11.4 installed with
delta-rs,numpy, andpolarspackages installed.
Generating Synthetic Logs
To provide an easy SecOps/SecDataOps-relevant dataset to write into Delta Lake, the script for this section will create a quarter million records representing a very basic network flow log you may get from an IDS or public cloud flow log.
Before starting, ensure that you modify the values for S3_BUCKET_NAME, S3_DELTA_PATH, and S3_BUCKET_LOCATION at the beginning of the script underneath the imports as shown below.
import numpy as np
import polars as pl
import ipaddress
import datetime
from hashlib import sha256
from deltalake import write_deltalake
S3_BUCKET_NAME = ""
S3_DELTA_PATH = f"s3://{S3_BUCKET_NAME}/deltalake/source=query_blog_lakehouse"
S3_BUCKET_LOCATION = ""
TOTAL_RECORDS = 250_000On a 32GB RAM MacOS laptop with Darwin Kernel Version 22.6.0, the entire script should generate the data set and upload to S3 in under 25 seconds, your speed will vary, you can use an EC2 instance with a S3 Gateway Endpoint to accelerate this time and accommodate even larger datasets.
The full schema can be found in the generateSyntheticNetworkLogs() function along with the code to properly format the event_time column in the dataset and extract the partition data from it with Polars, as shown below. This will automatically happen when you execute the script.
def generateSyntheticNetworkLogs(totalRecords: int) -> pl.DataFrame:
"""Assemble the synthetic logs"""
privateIps = generatePrivateIps(totalRecords)
publicIps = generatePublicIps(totalRecords)
timestamps = generateSyntheticTimestamps(totalRecords)
eventIds = generateEventIds(privateIps, publicIps, timestamps)
df = pl.DataFrame({
"event_time": timestamps,
"event_id": eventIds,
"internal_ip": privateIps,
"internal_port": np.random.choice(INTERNAL_PORTS, size=totalRecords),
"client_ip": publicIps,
"client_port": np.random.randint(*CLIENT_PORTS, size=totalRecords),
"direction": np.random.choice(DIRECTIONS, size=totalRecords),
"action": np.random.choice(ACTIONS, size=totalRecords),
"total_bytes": np.random.randint(*TOTAL_BYTES_RANGE, size=totalRecords),
"total_packets": np.random.randint(*TOTAL_PACKETS_RANGE, size=totalRecords),
})
df = df.with_columns(
pl.col("event_time").str.strptime(pl.Datetime, "%Y-%m-%dT%H:%M:%S.%f", strict=False).alias("event_time")
)
df = df.with_columns(
pl.col("event_time").dt.year().cast(pl.Int32).alias("year"),
pl.col("event_time").dt.month().cast(pl.Int32).alias("month"),
pl.col("event_time").dt.day().cast(pl.Int32).alias("day")
)
return dfCreating a Delta Lake table
The easiest way to create a Delta Lake table is using the delta-rs library which is a Python utility that allows you to write a Delta Lake table to any number of locations with a great amount of control over compression, bloom filters, partitions, and write strategy (e.g., append, overwrite, merge). For more information, refer to the official documentation here.
The write_deltalake method accepts a path, a DataFrame (Pandas or Polars) or an Apache Arrow Table, the mode, partitioning scheme, and specific storage options (such as the AWS Region). The DataFrame is generated using Polars which provides a significant speed advantage over Pandas, in my own benchmarking, swapping pandas and random for polars and np.random reduced the run time of this script from nearly 18 minutes to under 30 seconds!
You can modify the partition_by command and modify the df.with_columns() method from the generateSyntheticNetworkLogs() function if you wanted to remove or add more partitions such as hour or minute-level specificity. Once complete, you will see your partition data as well as the _delta_log metadata folder within your specific S3_DELTA_PATH as shown below.
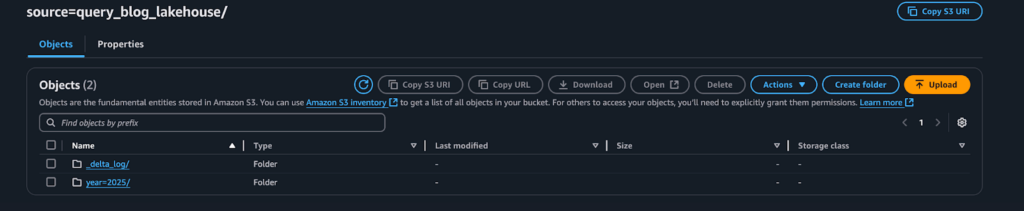
Interacting with _delta_log
The _delta_log path, as explained earlier, is what contains the metadata about the table, partitions, and is what keeps track of writes, schema evolution, and helps to ensure ACID compliance. As you continue to write data and add partitions into your various Delta Lake tables, more _delta_log files will be written that will keep track of the table metadata and these additions, with stats and specific schema details added.
Using the AWS CLI, you can explore the data within them using jq as well to pretty print it. For instance, the following command will print the entirety of the first _delta_log entry: aws s3 cp s3://$BUCKET_NAME/deltalake/source=query_blog_lakehouse/_delta_log/00000000000000000000.json - | jq .
If you wanted to see a specific element, such as the metadata which contains the table ID, name, description, schema and partitioning data, and other details you can modify the came in the following way: aws s3 cp s3://$BUCKET_NAME/deltalake/source=query_blog_lakehouse/_delta_log/00000000000000000000.json - | jq .metaData.
That will give you an output similar to the below screenshot. There are not a lot of operational reasons to interact with _delta_log outside of governance and change tracking, you can retrieve table details and schema information using other query engines and mechanisms.

In the next section you will learn how to query the data using DuckDB, which has built in read support for Delta Lake.
Querying Delta Lake with DuckDB
In the previous section you learned a simple way to generate synthetic security-relevant data and write Delta Lake tables to S3 as well as interact with the _delta_log. In this section, you will learn how to read and query Delta Lake tables in S3 using DuckDB. DuckDB is a vectorized in-memory analytics database–also known as a Online Analytics Processing (OLAP) database–that provides analysts and engineers a lightweight and performant way to query data in memory using SQL.
Download the Python script with VSCode Jupyter notebook cells from our GitHub repository here.
For more information about DuckDB, and for some beginner SQL lessons that can be relevant to SecOps and SecDataOps analysts and engineers, refer to our blog Introductory SQL for SecOps: Exploratory Data Analysis with DuckDB. You will learn how to install DuckDB as well as the Python library for DuckDB, refer there for installation and configuration information for running Notebooks on VSCode.
To set up, ensure that you enter the same S3 Bucket name that you used to write your Delta Lake table and execute both of the top cells afterwards.
# %%
import duckdb
S3_BUCKET_NAME = ""
S3_DELTA_PATH = f"s3://{S3_BUCKET_NAME}/deltalake/source=query_blog_lakehouse"
# %%
duckdb.sql(f"""
CREATE SECRET delta_lake (
TYPE S3,
PROVIDER credential_chain
)
"""
)
print("Created S3 Secret!")Retrieve daily total volumes
The first query counts events per day, demonstrating partitioning effectiveness. This can be useful to approximate data volumes over a given time period, based on your partition scheme. This data can be used to inform future migrations or to ensure that data synced from an upstream source such as a Security Information and Event Management (SIEM) tool or another data lake is as expected.
SELECT
year,
month,
day,
COUNT(*) AS event_count
FROM delta_scan('{S3_DELTA_PATH}')
GROUP BY year, month, day
ORDER BY year DESC, month DESC, day DESCThis query demonstrates the concepts of aggregation, counting, partitioning, and ordering.
Finding unique allowed inbound requests
The second query will locate unique external IP addresses (client_ip) that are inbound into your environment, that were allowed (not dropped or blocked), and were not attempting to reach HTTP or HTTPS data. Any other combination could be used, such as also excluding known-bengin client_ip or internal_ip entries that are expected to receive traffic such as honeypots or proxies.
This type of query could be useful to interdict specific traffic patterns that come through a firewall or NIDS appliance, with DuckDB, you could save the data into a CSV for more manual parsing. Additionally, you could use SQL JOINS with DuckDB to join against a table that contains IOCs or known malicious hosts to detect network-borne attacks.
SELECT DISTINCT
client_ip
FROM delta_scan('{S3_DELTA_PATH}')
WHERE direction = 'in'
AND action NOT IN ('block', 'drop')
AND internal_port NOT IN (80, 443)This query demonstrates the concepts of filtering, deduplication, and applying exclusion conditions with predicates.
Aggregate Top 20 suspicious external IPs
The third query uses summary aggregation instead of simply retrieving all of the unique client_ip. The same filtering and exclusion conditions are used, however, only the top 20 (using LIMIT 20) client_ip entries are retrieved and are ordered by the total requests.
This can be useful for determining if there are network floods originating from suspicious external IPs, this query could be further fine tuned by specifying a more specific port range as well as analyzing the size of the requests by bytes and/or packets. Again, using DuckDB’s ability to write to Parquet or CSV, this data could also be visualized using business intelligence or analytics tools.
SELECT
client_ip,
COUNT(*) AS event_count
FROM delta_scan('{S3_DELTA_PATH}')
WHERE direction = 'in'
AND action NOT IN ('block', 'drop')
AND internal_port NOT IN (80, 443)
GROUP BY client_ip
ORDER BY event_count DESC
LIMIT 20This query demonstrates the concepts of filtering, deduplication, and applying exclusion conditions with predicates along with aggregation and ordering.
Track Blocked HTTPS traffic with a Window Function
The fourth query filters for blocked connections on port 443 (typically HTTPS traffic) and demonstrates the usage of a window function. By using ROW_NUMBER() to assign a unique ranking to each blocked connection per internal_ip it partitions by internal_ip to group records by each internal system under attack.
SecDataOps teams could use a window function of this style to identify systems that are frequently targeted by HTTPS-based attacks, such as desync attacks. It can be useful to analyze attack patterns over time to detect DDoS attempts or malicious bot activity. With additional summary aggregation and joins, SecDataOps teams can further fine-tune their list of hosts to deploy a threat hunt against or to deploy countermeasures onto.
SELECT
event_time,
client_ip,
internal_ip,
internal_port,
client_port,
ROW_NUMBER() OVER (PARTITION BY internal_ip ORDER BY event_time DESC) AS row_num
FROM delta_scan('{S3_DELTA_PATH}')
WHERE action = 'block' AND internal_port = 443This query demonstrates the concepts of specific filtering and using a window function to partition and aggregate impacted hosts, versus the usage of summary aggregation.
Identify large outbound data transfers
The fifth and final query demonstrates the usage of the `SUM()` operator and summary aggregation combined to find the top ten `client_ip` entries with the most allowed outbound data transfers and sorts them based on the total bytes that were transferred. This is no different from the previous summary aggregations other than the usage of `SUM()` instead of `COUNT()`.
SecDataOps teams could use this query to investigate post-blast impact of an incident or simply to help with cost optimization use cases to locate hosts that are transferring the most data across the wire. This query is useful for determining the impact of data exfiltration from a raw network statistics view, or identifying hosts that contribute the most host-based logs to another Delta Lake table, or otherwise. Finally, potential insider threats could be discovered or investigated with this query, especially when correlated against an asset management dataset as well as a list of “Movers, Joiners, Leavers” from an ERP tool.
SELECT
client_ip,
SUM(total_bytes) AS total_transfer
FROM delta_scan('{S3_DELTA_PATH}')
WHERE action NOT IN ('block','drop')
AND direction = 'outbound'
GROUP BY client_ip
ORDER BY total_transfer DESC
LIMIT 10This query demonstrates summary aggregations with data summation and ordering.
In this section you learned five different queries that match the use case of the synthetic network logs. You learned how to use DuckDB to implement a variety of SQL query patterns and how it can read Delta Lake tables natively. Armed with this knowledge, you can expand further to schedule DuckDB queries to use for detection engineering use cases or otherwise!
Conclusion
Delta Lake offers a practical and scalable solution for security teams struggling with the limitations of traditional SIEMs and log management tools. By leveraging its open table format, ACID compliance, and high-performance query capabilities, security teams can efficiently store and analyze high-velocity security data from firewalls, EDRs, IDS, and other telemetry sources. Delta’s ability to decouple compute from storage provides cost savings while enabling flexible, real-time threat detection and long-term log retention.
By adopting Delta Lake within a SecDataOps framework, security teams gain control over their data, avoiding vendor-specific data formats while maintaining full-fidelity logs. Its compatibility with Python, PySpark, DuckDB, Athena, and other tools ensures that both security analysts and engineers can iterate quickly on detections and investigations without unnecessary delays. With support for massive-scale ingestion and structured querying, Delta Lake is a powerful addition to any security data stack, bringing SIEM-like capabilities to an open and scalable architecture.
If you would rather build out your Delta Lake tables but leave the SQL and detection engineering to someone else, check out the Query Federated Search platform! We seamlessly integrate with Delta Lake tables in Amazon S3 that are indexed by the AWS Glue Catalog using our Amazon Athena Connector.
If you would like us to support Delta Lake for another cloud provider, please contact product@query.ai! If you have any questions about how federated search can help you seamlessly parallelize queries, handle federated analytics, federated detections, and normalization contact our sales team here!
Stay Dangerous.