
Introduction
The security industry at-large likes to brand data as “the new oil”, or more frequently, as “gravity”. I disagree. Data is mass, like super dense tungsten ore or cobalt-based alloys like Inconel. The only way we can move these large masses of ore is via heavy machinery and heavy logistics, the analogue to that in Security Data Operations is the use of pipelining. Ask three people about pipeline implementation and you’ll get three different answers. Consider this a fourth.
Our co-founder, Dhiraj Sharan, has written about security data pipelines back in August 2023, we’ve also addressed it in several other blogs such as this entry on Security Data Management (the consensus acronym is SDPP: Security Data Pipeline Platform). You may have caught our announcement on “writing to gold” when we had a closed beta for this feature, or earlier still, when we attempted an open-source project for Falcon Data Replicator (FDR). Much like the rest of you, our thinking has changed on pipelines-as-a-feature, and you know what, we’re on board. Heck, we even wrote a free whitepaper about it!
The purpose of this blog is to educate you on our way of writing data the right way, to enable quicker access to the data that matters to you via our Security Data Mesh and Federated Search capabilities, and talk about the road ahead. Are you ready?
The Problem Statement
“How the f&$k are we going to move all this data?!”
– You (probably)
Much like we do not ship Inconel on the back of mules or rucksack-equipped laborers, one does not simply move data with small scripts and infrastructure. As the amount of capabilities increases, I believe that data exhaust exponentially increases. For every new category: CNAPP, IGA, NGFW, XDR, and so on – you have exponentially new sources of data from these different tools (and their APIs, if they have one). So you need an effective way to move it, while Cron jobs and scheduled PowerShell or Bash scripts may have once ruled the day, there is just way too much data to do it that way.
Security Data Operations teams need access to the right data to effectively do their jobs, enable decision support, and ultimately collapse attack paths, treat identified risks, search for novel tradecraft, track remediation efforts, and myriad other discrete tasks. The great irony is that despite having more capable tools that are purpose built to contain or detect threats in specific mediums – cloud, code, browser, AI, etc. – even more data is needed, not less.
So now the problem shifts from not having awareness or visibility into a specific medium, or against a specific class of threats (and subsequent risks), but lacking access to data. Our opinion has led us to building a Security Data Mesh; not as an architectural pattern but as a platform that enables customers to search disparate, decentralized data sources in a centralized manner and bring correlated and collated data. However, some sources of data don’t have strong APIs that support pagination, filtering, asynchronous requests, or sometimes they don’t have APIs at all.
Okay, easy, have the customer move the data. There’s that problem. Not just the how but how to do it effectively, let alone where to put it all. Several technologies have tried to address this, the SIEM 1.0 platforms (ArcSight, Splunk, et al), the “SIEM 2.0” platforms such as Extended Detection and Response (XDR) and User & Entity Behavior Analytics (UEBA) platforms, and the new “SIEM-Like” vendors such as Detection-as-Code platforms and native security data lakehouse companies. Of course, all of those players are economically incentivized to capture your data, it is their moat after all – that’s why they all insist they are the best spot for data.
It still doesn’t solve the how, and no, Heavy Forwarders and Syslog Servers do not count! Modern Security Data Operations forces teams to pay attention to what data they want, where they’ll put it, and what it will be used for – and use that complex web of requirements and constraints to house each “domain” of data in the right place. That is why SDPPs as a whole have largely taken off, because they’ve tried to service the main sources of high volume logs and more or less move it in a performant and cost-effective way for customers to pick up somewhere else: be it a SIEM 1.0, 2.0, or “SIEM-like” platform. To further complicate matters, some of your SDPPs are now also saying they’re Detection platforms, or they end up storing your data, so XDR 2.0?
In reality, that is more than a single problem statement, those aforementioned examples are entire corpora of problems unto themselves. So, naturally, we figured there was a better way.
I Got 99 Problems, Data Ain’t One
There are numerous patterns for moving data. Streaming has variety, batching has variety, there are hybrid patterns, backfill, redrive policies, dead letter queues…I can hear your eyes crystallized and glazing over from here, I get it. Security teams, whether they abided by SecDataOps or not, do not want to be data engineers. While that saddens me a bit, the problem statement became: “How can I make a security engineer a data engineer, without actually making them change their jobs?”.
To that end, we coined the catch phrase “Write data, the right way”. The right way? That’s platform dependent, but instead of creating complex User Experiences and logarithmically more complicated backend infrastructure, we just handle “the right way” opaquely. You don’t need to worry about backpressure, or how many minimum files to keep open, or how to rightsize Kubernetes or containerized workloads. You don’t need to worry about compression codecs, or what file type to choose, or what a partition is. Query Security Data Pipelines completely removes all of that guesswork and required domain expertise away, and will handle it automatically for you.
You have more than enough problems as it is, the last thing a team needs is to be presented with confusing and contradictory parameters and configurations they need to worry about. Simply pick a Source (any Query Connector), pick a Destination (of which we have five, for now), pick a cadence, and then pick an additional time window if you know your source has delays in writing logs. From there, the data is written the right way to the various destinations from which you can do what you want.
In this release, we allow 30 minute, 60 minute, and 24 hour recurrence windows that we will expand on (and eventually allow configuration). This is both how often the pipeline will run, and how far back it will look for new data. This unlocks use cases such as moving data that is slow behind an API (like Microsoft Graph), but fast in a data warehouse or log management platform. This allows you to retain logs far beyond allowable API windows for search, and even allows you to migrate SIEMs or other data lakes to different destinations.
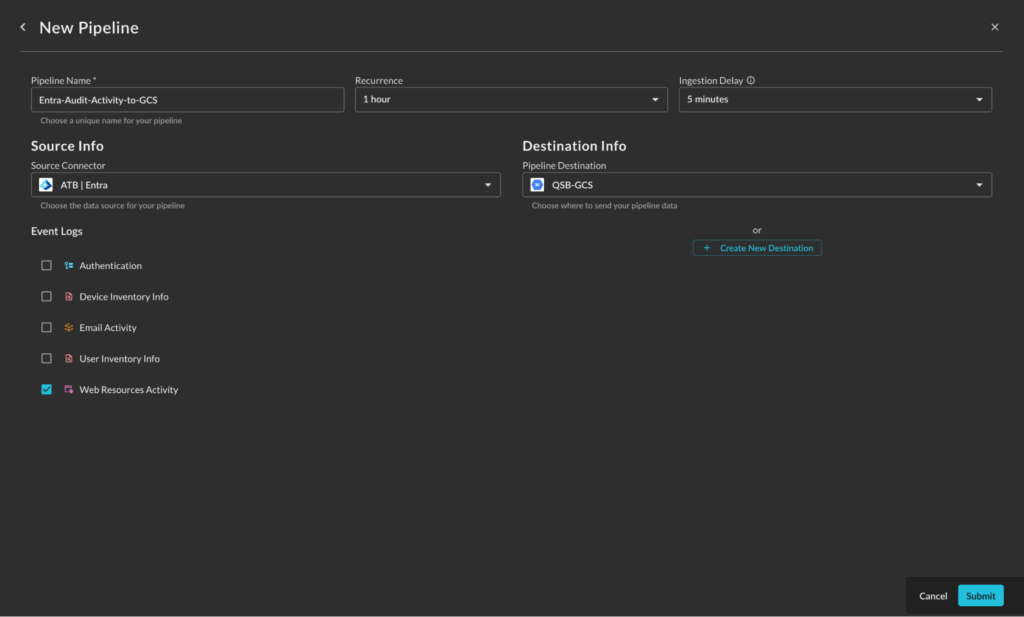
We went with a micro-batching architecture that does all of the Extraction, Transformation, and Loading (ETL) for you. Our data model is the Open Cybersecurity Schema Framework (OCSF), it’s vendor agnostic and minimally lossy (depending on the log source), and allows greater utility by unifying and standardizing types. Instead of keeping track of the myriad ways an IP address, hostname, or other data point may be defined, you have common attributes in the data model to use. This will make JOIN operations, detection authorship, and analytics or feature engineering much easier on your SecDataOps teams. Don’t remember if your asset IP is called PrivateIpAddress, aip, device_ip, or Ipv4Address? Cool, it’s now device.ip.
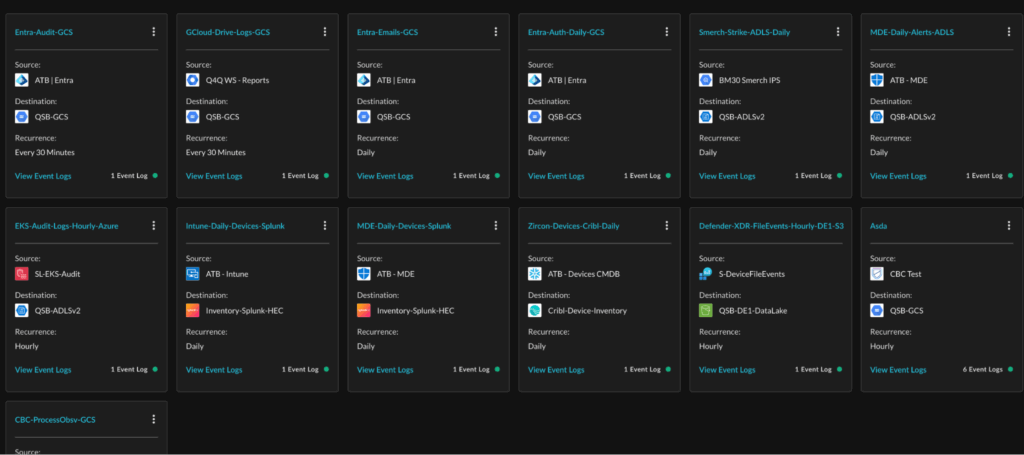
Right now, we allow the following Destinations to receive events from our Data Mesh, the linked documentation provides details on the configuration as well as down-stream enablement and interoperability with Query Federated Search.
- Amazon Simple Storage Service (S3) buckets,
- Azure Storage Account Blobs / Azure Data Lake Service V2,
- Cribl Stream – Bulk HTTP(S) Source,
- Google Cloud Storage (GCS) buckets; and
- Splunk HTTP Event Collectors (HEC)
With Amazon S3, you can easily crawl the written data to onboard it onto AWS Glue Data Catalog for usage with our Athena or Redshift Connectors. Azure Blob/ADLSv2 can be easily ingested in Azure Data Explorer, and likewise, GCS data can be easily onboarded into Google BigQuery. With Cribl, you can use our Cribl Search Connector to hit the data in Cribl Lake Datasets, and you can naturally search Splunk with our Connector. The advantages of the Federated Search Connectors provider is massively parallelized, fine-tuned query translation, and in-situ normalization. No joins, no unions, no pre-processing for enrichment – write analytics, detections, or conduct searches from the UI, our API, or via our Splunk App.
We aren’t done there, however, there is more work to be done to make this data-as-mass problem seem less insurmountable.
The Road Ahead
Rather than bludgeon you with prose, I’ll give you a bullet list which should be familiar given all the list-heavy AI slop that passes as good product marketing content!
- MOAR (!) Destinations: While you can go from GCS to BigQuery or Azure Blob to ADX, those platforms offer native writes. As does Amazon Security Lake, Snowflake, Databricks, and Clickhouse Cloud. All of this is up for consideration, we’ll likely tackle Snowflake first.
- Fine Grained Recurrence: Some data may need to be moved faster, some of it may only need a sync every week or every month. We can easily adapt to relative-time, and are looking at offering absolute time or Cron-expressions if you so choose.
- Specific Filtering: We are looking for ways to expose our OCSF mappings in such a way you can choose what fields to include for specific use cases. Your Detection Findings may have rich asset details you want to reap, or your Vulnerability Findings may have CVE-specific metadata and threat intelligence you’d rather use as a secondary source instead of the entire finding. Whatever it is, we want to give you more control of what exact data points are sent on the wire.
- Expanded Source Support: This release includes support for our existing 50+ connectors. We have some prototypes in the works and will soon solve for heavy hitters like firewalls, additional cloud security tools, and host appliances.
- Query Managed Syslog Receiver: You send us CEF-compliant Syslog, we do “the hard stuff”, and spit the data out normalized to a destination.
- Composable Pipelines: This will shift some heavy lifting back to you, but there is merit to some of more the detailed SDPPs, if there is a REST API that you can give us access to it is likely we can provide a mechanism for you to move data out, use our ETL tech, and push it somewhere else
- SecDataOps Co-workers: We can help you via our SecDataOps Workshop or use our Agent Framework to provide data engineering services for muddier, brownfield use cases, including tamping down on signal or unnecessary fields.
There is likely more we’ll come up with, and eventually you’ll read another one of these blogs (hopefully with less lists) announcing our V2. Until then, Pipelines are generally available for any Query customer and will be included with Query licensing at no additional charge during the launch period. We’re excited to see what you’ll build!
Conclusion
Writing data has never been easier. Select Source, select a Time, select a Destination, and go! The team worked very hard on this feature and delivered some differentiated tech underneath. We are looking forward to reuse on other planned features on the roadmap.
Be sure to follow Query on LinkedIn, request a demo, and get yourself the ultimate Security Data Mesh that can run circles around your current SDPP.
SecDataOps Savages are standing by, ready to enable you, with data.
Stay Dangerous.