
The advent of cloud, SaaS, and hybrid work environments have made conventional security data centralization pipelines less practical. The future is more flexibility and visibility, with less data shuffling and storage costs.
Security data is now more heterogeneous, omnipresent, and expansive than ever, but the pipeline for log management has not adapted. Organizations are seeking the flexibility to choose best of breed vs. corporate standardization on single-vendor storage. Storage is typically one of the largest expenses for cybersecurity teams, and choosing the wrong option can quickly lead to overspending. In this article, we will talk about the security data pipeline problems and detail how Query enables choice and flexibility for log storage and searchability.
Conventional Security Data Pipeline
The conventional security data pipeline has been to move and route security data to SIEM and log management solutions. It looks like:
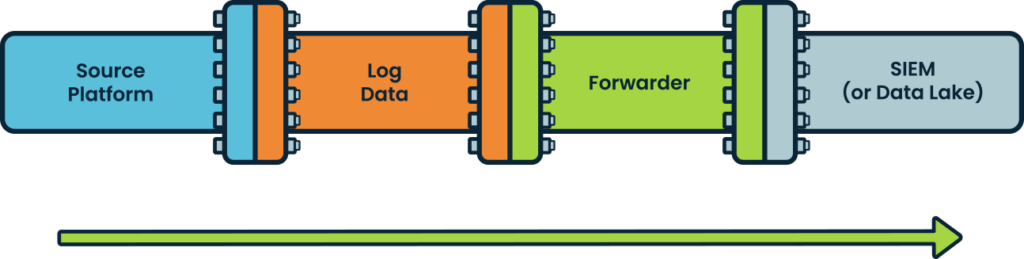
This unidirectional pipeline works fine within the confines of any individual network environment, such as a traditional on-prem production network. But the proliferation of environments containing security-relevant data breaks this traditional pipeline, as the data now resides everywhere, not just in the SIEM. As per Help Net Security, 87% of enterprises have already embraced multi-cloud and 72% are running hybrid cloud environments, underscoring the expanding cornucopia of data sources. .
The need for access and visibility into data outside of the SIEM has forced analysts to pivot out of their SIEM to access data from other sources. SIEM, data lakes, and other data centralization vendors would happily ingest all of this ‘unhomed’ data, as that leads to more revenue for them. But force-fitting into the conventional data pipeline – as SIEM vendors would want – leads to increased complexity and costs.
Ideally, you would not put the following data into your SIEM, as they are very high volume sources that inflate centralization costs:
- DNS logs
- EDR data
- Network traffic data
- Web proxy data
Unfortunately, it can be challenging to manage multiple log storage solutions, especially if they are located in different locations or use different technologies.
How do you leave logs in their native repositories, separate data ponds (not lakes!), or in lower cost blob storage like Amazon S3?
It’s time to look beyond traditional log-centric data-centralization pipelines and embrace API-based direct data access. Cloud has been adopted to an extent that organizations have multiple cloud accounts, often across multiple cloud providers, and are being built and managed in an API-centric manner. Services interact with each other at any time from anywhere via APIs.
Applications have become de-facto SaaS. SaaS vendors prefer exposing API-based access vs. dealing with traditional log pipeline based transformers, parsers, etc. With zero-perimeter work environments, APIs are the way to interact. Hence, traditional pipelines are becoming outdated, and API-based data access for visibility and analysis is the way to go.
SaaS presents a big monitoring and visibility challenge for traditional pipelines built around transferring data. The guardrails used in private networks are no longer applicable. You can’t easily monitor something you don’t host and control. Traditional private network boundaries and SIEM rules based upon it are almost irrelevant.
Not having visibility into their data is like flying blind, but is commonplace today because of the limitation around the traditional pipeline.
As per McKinsey, CISOs are as serious as ever about closing the log visibility gap. Just three years ago the average enterprise saw only 30 percent of what was happening, but are now pushing to get to 65 to 80 percent over the next three years. The critical gap needed to enable this is a security console that uses APIs and stitch data on-demand from their heterogeneous storage solutions.
Centralization costs are prohibitive with data growth. Solving visibility problems needs out-of-box thinking. Let’s talk about a security console that can solve these problems.
Solution: Security console that uses APIs to search data, across multiple vendors, platforms, and locations
Security data storage transcends multiple platforms and vendors, and there is a need for a security console that can work with data in-place in third party platforms. This new approach to an age-old cybersecurity problem has now emerged.
Query is a security console that provides federated search over data spread across multiple vendors, platforms, and locations.
Replace security data pipeline with federated search over API interconnect
Instead of the conventional security data pipeline built on moving data, the new “pipeline” is completely different as it is designed to transfer only search questions/queries and their answers. Queries move left to right and answers move right to left, all done just-in-time, as compared to a unidirectional data movement pipeline.
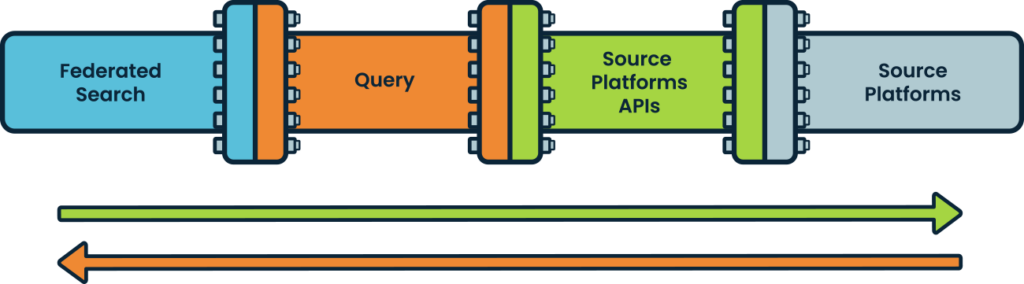
Source platforms can be your EDR, NDR, Email Security, CMDB, Cloud Services, threat-intelligence sources, ticketing platform, Identity & HR platform, SaaS Applications, or even your SIEM.
Future-proof your Security Operations
With this new approach, you can reduce movement of data, query in-place with federated search, reduce your licensing and infrastructure costs, and dramatically increase the choice and flexibility available to you.
Having flexible log storage options allows cybersecurity teams to adapt to changing needs over time as organizations grow and evolve. Adopting the API-based federated search approach keeps a range of storage options available and future-proofs your security operations. You are no longer hostage to a single vendor.