
Introduction
Amazon Web Services (AWS) Transit Gateway (TGW) is an AWS that acts as a highly scalable cloud network router. Released in November 2018, TGW allows you to connect many different Amazon Virtual Private Clouds (VPCs), AWS Direct Connect (DX) Gateways, and AWS Site-to-Site VPNs together in a centralized hub. This greatly simplifies hybrid and inter-region and inter-Account connectivity and reduces the burden on network operations teams needing to maintain additional VPN and VPC peering connections.
Just like Amazon VPCs, AWS TGWs produce Flow Logs, which enable the capturing of information about IP traffic going to and from your TGWs. Flow logs capture data outside the path of TGW network traffic and do not reduce throughput or latency. While TGW flow logs do not capture interface-based traffic like VPC flow logs, they capture the flow from the various attachments within the TGW and log information from the source and destination VPCs, Availability Zones, AWS services, and more network connectivity information.
Just like VPC flow logs, TGW flow logs support custom logging formats, support the same destinations, and support the same file formats. However, these logs are not automatically aggregated for you, requiring manual intervention or clever automation to centralize. Likewise, while VPC flow logs are automatically collected by Amazon Security Lake, these do not account for TGW flow logs.
In this blog you will learn how to work with and query logs from already existing TGW flow log configurations, both in flat text files as well as in Parquet. Additionally, you will learn how to query potentially interesting points of information from the logs using SQL. Finally, you will learn how to deploy an automation solution that will aid in the centralization of TGW flow logs and how to build a multi-account, multi-region security data lake for them.
Prerequisites and Constraints
For the content of this blog you will need access to an AWS Account with an AWS Transit Gateway deployed with at least a single attachment, and have permissions to work with the APIs for Transit Gateway, flow log configurations, AWS Glue, Amazon Athena, AWS CloudFormation, and Amazon S3.
The content for this blog is written for the default version of Transit Gateway flow logs, which is version 6 as of 11 SEP 2024. If you are using custom flow logs, or older default versions, you will need to modify several SQL statements contained in the blog. The manual solution to index pre-existing or newly created TGW flow logs only works with text file-based logs stored in Amazon S3 buckets.
For more information on working with TGW logs in other locations, refer to the Transit Gateway Flow Logs records in Amazon CloudWatch Logs and/or Transit Gateway Flow Logs records in Amazon Data Firehose sections of the AWS Transit Gateway user documentation.
Transit Gateway Overview
AWS Transit Gateway (TGW) makes it possible to build hybrid, multi-cloud, and/or cross-account and cross-region hub-and-spoke network architectures. Within the TGW, all traffic is routed through the AWS network backbone to your intended target network. This is beneficial for several reasons:
- Simplified network architecture and operations
- Less reliance on AWS S2S VPN and VPC peering connections
- Meet regulatory requirements and other compliance technical controls that require traffic to be controlled within the same network boundary
- Increased visibility into cross-boundary communications
TGWs are easy to connect, the main architectural component being the Gateway itself. From the Gateway, you create Attachments into different VPCs, VPNs, other TGWs, or use a Transit Gateway Connect Attachment into third party appliances such as a Software Defined Wide Area Network (SD-WAN) or otherwise.
Per Attachment, there are specific options such as enabling DNS and IPv6 support for VPCs or enabling VPN Acceleration and Border Gateway Protocol (BGP) dynamic routing options for VPNs. The intricacies of each set up and their limitations are out of scope for this blog.
Transit Gateway Flow Logs
While flow logs, especially VPC flow logs, are typically used for network operations and application team troubleshooting or to fulfill compliance requirements – there are more active security use cases that they are useful for.
For instance, imagine if you received a suspicious connection alert from Amazon GuardDuty or from an EDR tool and wanted to investigate further, you can search for the specific Elastic Network Interface (ENI) ID or the IP address in the flow logs. From there, you can filter down for allowed connections that egress from AWS, this can be used to determine if connectivity to a Command and Control (C2) server was made or to some other malicious beacon.
If your AWS network architecture was such that all egress traffic exited into a shared or centralized TGW before passing through outbound filtering via forward proxies, AWS Network Firewall, or another inspection layer – it can be much harder to keep track of the traffic. You would immediately lose visibility as it moved through the Transit Gateway and only have half of the picture.
If the investigation was oriented around a “post-blast” assessment to assess potential damage or interdict any lateral movement, TGW flow logs are immensely useful, if TGWs are a major part of your network architecture. Using the flow logs you can map the flows as they move from VPC to VPC or another other attachment and to interdict where and which TGW the traffic flows. When used alongside other sources of telemetry – such as CloudTrail Management Events to follow up on new attachments being created, or Application Load Balancing or AWS WAF logs to track the traffic from the inception point – the TGW flow logs can also be an important piece of context logging.
Like VPC flow logs, TGW flow logs have their own format and their own field values. This blog focuses on the default (version 6) but can be modified to accommodate any other custom formatting. For more information, refer to the Transit Gateway Flow Log records section of the AWS Transit Gateway user documentation.
TGW flow logs, like their VPC flow log cousins, are not without their limitations. The primary limitation is that flow logs are virtualized and are captured and aggregated outside of the path of traffic. While this is beneficial for not impacting throughput or latency, it means that not every single event is captured, there is an inherent lossiness with the logs. For further reading, refer to our blog Limitations and Applicability of Flow Logs, where limitations, features, and more use cases are discussed.
Working with Existing Flow Logs
As started in the Prerequisites section, this section of the blog is focused on working with existing, text-based, default (version 6) formatted TGW flow logs. You may be required to modify the SQL code contained to work with your logs.
Within AWS, for data stored in Amazon S3 buckets, the best way to work with this data for exploratory data analysis is to use Amazon Athena. Athena is an AWS managed service that is based on PrestoDB and Trino that allows you to write SQL queries against files stored in Amazon S3. To catalog the schema of the data, you can use AWS Glue Crawlers to autodiscover the data or manually submit SQL Data Definition Language (DDL) statements to create the table if you already know the schema. For further information, refer to the Understand your network traffic trends using AWS Transit Gateway Flow Logs entry in the AWS Network & Content Delivery blog.
Creating a Table
In Amazon Athena, to create an external table you must define the specific schema, and pass in several parameters that define the format, field termination, line termination, storage format, location (your S3 bucket), and specific properties about the table. The following SQL query accounts for the formatting parameters for GZIP text flat files within a specific top-level directory where flow logs are stored. The header line is also skipped as the format is passed in every single saved file that stores aggregated flow logs.
Note you must modify the LOCATION argument to point the S3 URI with the directory path of your flow logs. The natural parent directory to define this at is either AWSLogs/ if you store multiple account’s worth of logs in a single S3 bucket path, or at AWSLogs/account_id/vpcflowlogs/ if there is only one account. Amazon Athena uses the LOCATION argument to determine which depth to use the Amazon S3 ListObjects API at. Having a more specific path helps to speed this process up.
CREATE EXTERNAL TABLE IF NOT EXISTS tgw_flow_logs (
version STRING,
resource_type STRING,
account_id STRING,
tgw_id STRING,
tgw_attachment_id STRING,
tgw_src_vpc_account_id STRING,
tgw_dst_vpc_account_id STRING,
tgw_src_vpc_id STRING,
tgw_dst_vpc_id STRING,
tgw_src_subnet_id STRING,
tgw_dst_subnet_id STRING,
tgw_src_eni STRING,
tgw_dst_eni STRING,
tgw_src_az_id STRING,
tgw_dst_az_id STRING,
tgw_pair_attachment_id STRING,
srcaddr STRING,
dstaddr STRING,
srcport INT,
dstport INT,
protocol STRING,
packets BIGINT,
bytes BIGINT,
start BIGINT,
end BIGINT,
log_status STRING,
type STRING,
packets_lost_no_route BIGINT,
packets_lost_blackhole BIGINT,
packets_lost_mtu_exceeded BIGINT,
packets_lost_ttl_expired BIGINT,
tcp_flags STRING,
region STRING,
flow_direction STRING,
pkt_src_aws_service STRING,
pkt_dst_aws_service STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 's3://bucket_name/AWSLogs/account_id/vpcflowlogs/'
TBLPROPERTIES (
'compressionType'='GZIP',
'skip.header.line.count'='1'
)If the query succeeded, you will receive a Query successful message in the Amazon Athena console. If there are any failures, double check the LOCATION parameter, verify that you have logs in the directory path, verify you are using text formatted logs, and the flow log format. You may need to rearrange the order of the field names or remove/add certain field names depending on your exact format.
With a direct table definition, no further actions are required to maintain the table. The LOCATION parameter acts as the “pointer” to the S3 objects (your flow log files). Only if you provide a more specific path will you need to either create a new table, or delete and replace the table. Take care to properly optimize your SQL queries though, the more data there is to scan the more expensive Athena becomes. A small environment will likely create several smaller files with only a few dozen kilobytes which negatively affects query performance.
Querying Transit Gateway Flow Logs
To query the logs with Athena, consider the following query examples (this is not meant to be an exhaustive list nor a definitive guide). For more information, refer to the Run SQL queries in Amazon Athena section of the Amazon Athena Developer guide or refer to the Named Queries in this AWS CloudFormation template from AWS.
To create an aggregation of the top 50 source and destination addresses along with the total amount of bytes they’re responsible for transferring, execute the following SQL statement. The SUM() function will add up the values of the bytes field. Since this is an aggregation the GROUP BY statement is used to group rows of the same values into “summary rows”. In this case, you are aggregating the srcaddr and dstaddr fields. Finally, the ORDER BY statement is used to sort the bytes in a descending fashion with the LIMIT keyword used to limit the result set to 50 rows.
SELECT
SUM(bytes) as total_bytes,
srcaddr,
dstaddr
FROM "securitydata"."tgw_flow_logs"
GROUP BY srcaddr, dstaddr
ORDER by total_bytes DESC
LIMIT 50A similar aggregation is tracking the connected subnets with the highest amount of traffic, this can be useful for investigating cost overruns or as part of a security investigation tracking lateral movement or the source of network flooding attacks. The SQL statement is functionally the same, you will only request and aggregate on a different field name, and eschew the LIMIT keyword.
SELECT
SUM(bytes) as total_bytes,
tgw_src_subnet_id,
tgw_dst_subnet_id
FROM "securitydata"."tgw_flow_logs"
GROUP BY tgw_src_subnet_id, tgw_dst_subnet_id
ORDER by total_bytes DESCFor investigating TGW flow logs with data from VPC flow logs, one area to focus on is the Elastic Network Interface (ENI). ENIs are virtualized network interfaces that provide connectivity from AWS services into your VPC, such as Amazon EC2 instances, Lambda functions or ECS tasks, or load balancers and a myriad of other services.
If you have VPC flow logs where you intercepted a threat communicating from a compromised instance, you can check for lateral movement throughout the TGW by filtering for the specific ENI(s) using the WHERE statement and equality operators. Like most log fields in TGW, there is both a source and destination ENI. This data may not always be present, however, any non-matches will be ignored which keeps your resultset lean. Optionally, you can use the LIMIT keyword to keep the rows of data returned to a modest level.
SELECT
srcaddr,
dstaddr,
tgw_src_eni,
tgw_dst_eni
FROM "securitydata"."tgw_flow_logs"
WHERE tgw_src_eni = 'eni-12345678910' OR tgw_dst_eni = 'eni-12345678910'This was an extremely brief overview of the types of analysis you can do with Athena, refer to hyperlinked blogs and other resources for more information on implementation and inspiration on other queries. In the next section, you will learn how to create and query a partitioned table of existing TGW flow logs.
Creating a Partitioned Table
To offer better query performance (faster speeds, lower costs) consider utilizing partitions in your data. Partitions are logical “chunks” which separate your data into smaller sections for querying and organization. For instance, you can create partitions on the AWS Account ID the logs are sent from, or you can create time-based partitions. In the grander scheme, you can partition by any key within your dataset – choose a strategy that works best for the shape of your data and your query patterns.
You can restrict the amount of data scanned per Query to improve query performance and reduce cost by filtering on the partition key(s) in your query using the WHERE clause. Partitions in Athena are essentially pointers to specific directories within your S3 bucket folder structure where the data is stored.
There are multiple ways to work with partitions using Athena as well as AWS Glue Data Catalog, a metadata service that stores schema and partition information that can be used by Athena. The most straightforward way is to set your S3 directory structure up with Apache Hive style partitions, whose data paths contain key value pairs connected by equal signs (for example, country=us/ or year=2021/month=01/day=26/). With Hive style directories, you can use the MCSK REPAIR TABLE command to automatically load all of the new partitions.
For S3 directories that do not use Hive-style partitioning you must use the ALTER TABLE ADD PARTITION command to manually add your partitions. For further information refer to the Partition your data section of the Amazon Athena User Guide documentation, or the Work with partitioned data in AWS Glue entry in the AWS Big Data Blog. For more advanced use cases where there are more than one million partitions in your dataset, refer to the Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes entry in the AWS Big Data Blog to learn about working with indices.
For cases where you will not be using AWS Glue to automate the crawling and partition discovery within your dataset, you can use partition projection to automatically manage partitions. In partition projection, table properties are defined that contain partitioning templates that instruct Athena how to calculate the partitions during query time. There is a tradeoff here, while projection can be faster than pruning – that is, cutting down to the exact folders defined in explicit partitions – you must always specify the partitions in your queries which may complicate querying patterns.
To create a table with partition projection for TGW flow logs stored as text files, execute the following SQL statement. Note that you must replace the placeholder values in both the LOCATION and TBLPROPERTIES section of the query, notably within the storage.location.template argument.
CREATE EXTERNAL TABLE IF NOT EXISTS tgw_flow_logs_pp (
version STRING,
resource_type STRING,
account_id STRING,
tgw_id STRING,
tgw_attachment_id STRING,
tgw_src_vpc_account_id STRING,
tgw_dst_vpc_account_id STRING,
tgw_src_vpc_id STRING,
tgw_dst_vpc_id STRING,
tgw_src_subnet_id STRING,
tgw_dst_subnet_id STRING,
tgw_src_eni STRING,
tgw_dst_eni STRING,
tgw_src_az_id STRING,
tgw_dst_az_id STRING,
tgw_pair_attachment_id STRING,
srcaddr STRING,
dstaddr STRING,
srcport INT,
dstport INT,
protocol STRING,
packets BIGINT,
bytes BIGINT,
start BIGINT,
end BIGINT,
log_status STRING,
type STRING,
packets_lost_no_route BIGINT,
packets_lost_blackhole BIGINT,
packets_lost_mtu_exceeded BIGINT,
packets_lost_ttl_expired BIGINT,
tcp_flags STRING,
flow_direction STRING,
pkt_src_aws_service STRING,
pkt_dst_aws_service STRING
)
PARTITIONED BY (
region STRING,
year STRING,
month STRING,
day STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 's3://bucket_name/AWSLogs/acccount_id/vpcflowlogs/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.region.type'='enum',
'projection.region.values'='us-east-1,us-east-2,us-west-1,us-west-2',
'projection.year.type'='integer',
'projection.year.range'='2020,2030',
'projection.month.type'='integer',
'projection.month.range'='1,12',
'projection.day.type'='integer',
'projection.day.range'='1,31',
'storage.location.template'='s3://bucket_name/AWSLogs/acccount_id/vpcflowlogs/${region}/${year}/${month}/${day}/',
'skip.header.line.count'='1',
'compressionType'='GZIP'
)Compared to the non-partitioned CREATE TABLE SQL statement, there are a handful of notable differences. First, the PARTITIONED BY() clause is used to define the field names in the dataset to use in partitioning, in this case we are using the AWS region, year, month, and day. Next are the various arguments within TBLPROPERTIES that control enabling partition projection (project.enabled) and several other template arguments related to project (appended with projection.*).
Regarding AWS regions, as the value of the region is in the path of the TGW flow logs, an enum type is defined with a comma-separated value list of the regions expected. Modify this list to accommodate a larger amount of AWS regions. This similar style of defining enumerations for any other scalar partition field name can be used if you wanted to extend this to a field such as cost_center or organization_name, or otherwise.
As the dates are written numerically in the S3 directory structure for TGW flow logs, integer types along with ranges are defined for each day, month, and year in their respective partition arguments. The most important part of the TBLPROPERTIES definition is the storage.location.template argument that uses bash-style variables to help Athena understand how the partitions should be calculated and provided.
To query a partition projected table, you must always reference the partition keys within your SQL statement. Without it, Athena will not know where to look and cannot calculate the projections. This may hamper exploratory data analysis efforts for team members who do not know there is partition projection ahead of time. Other than that you will write your query as normal as shown below.
SELECT
srcaddr,
dstaddr
FROM tgw_flow_logs_pp
WHERE
region = 'us-east-2'
AND year = '2024'
AND month = '9'
AND day = '16'It is important to know that unless you have very high volumes of data (TB scale) collected across several transit gateways across a longer period of time, partition projection will be slower than a non-partitioned table used for simple exploratory data analysis or security operations.
In this section you learned how to work with partitioned tables in Amazon Athena. You learned about partition pruning versus partition projection, and use cases where one may be more advantageous – as well as disadvantageous – than the other. Finally, you learned how to use partition projection in your SQL statements and how to query tables with projection. In the next section you will learn about using an automated, centralized solution to collect, index, and partition TGW flow logs.
Automating multi-account Transit Gateway flow log collection
In the previous sections you learned how to create tables for TGW flow logs stored as text files, both partitioned and non-partitioned, and how to query them. This ad-hoc mechanism is beneficial to use during emergencies or for generic EDA and security operations use cases, but it does not scale.
The best way to collect TGW flow logs is to use the most up-to-date format and create a brand new flow log configuration that will collect the log files in Apache Parquet format and with Hive style partitioning enabled. Parquet is a columnar binary file format that is very read efficient for querying, and can be compressed to very small sizes versus text, CSV, and JSON data. Parquet is also used for several open table formats such as Apache Iceberg. For more information about Iceberg, refer to our blog: Amazon Athena and Apache Iceberg for Your SecDataOps Journey.
Parquet is also very efficient to crawl with AWS Glue Crawlers. Crawlers are an AWS service which interrogates various types of data stored in Amazon S3 and external connected data repositories, classifies their format, schema, properties, and writes the metadata into the AWS Glue Data Catalog. The Glue Data Catalog is the metadata store that contains information on tables, databases, schemas, and downstream location information and is used by Athena to facilitate querying data in S3. For more information, refer to the How Crawlers Work section of the AWS Glue User Guide.
Architecture
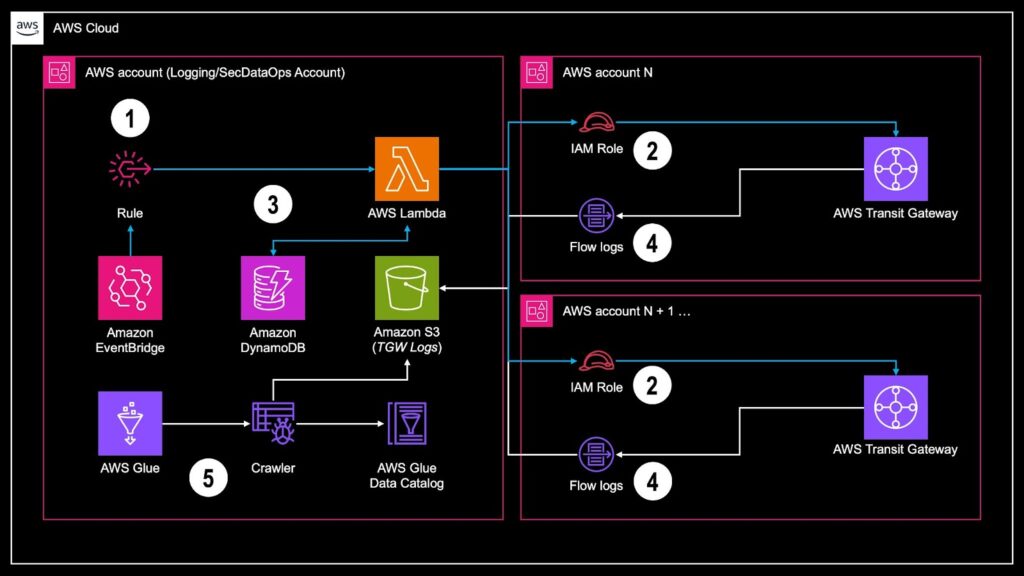
The solution architecture flow is as follows.
- An Amazon EventBridge time-based rule invokes an AWS Lambda function on a schedule (default 14 days).
- The Lambda function iterates through a list of AWS Accounts and opted-in AWS Regions and assumes an IAM Role. The Role allows for describing Transit Gateways and their flow logs, as well as creating new ones.
- The Lambda function checks if the Transit Gateway is present in an Amazon DynamoDB table, this is used to keep track of existing configurations on subsequent executions.
- If the Transit Gateway is not present in the DynamoDB table, a new flow log configuration is created which writes to a centralized bucket in Hive-like partitioned Parquet format.
- On a schedule, AWS Glue initiates a crawler to automatically catalog new data and add partitions into the AWS Glue Data Catalog for further analysis in Athena, Amazon EMR, or otherwise.
To successfully implement this solution, the following conditions must be met.
- The centralized location must be deployed in a Centralized Logging or Security Data Operations (SecDataOps) account that is a Delegated Administrator of at least one AWS service. This allows the account to access AWS Organizations APIs to enumerate AWS Accounts.
- If you want to include your own Centralized Logging or SecDataOps account in the collection, you must deploy a standalone CloudFormation Stack, as the Organization-wide deployment option for StackSets does not include the source account.
- The IAM Role used in Step 2 above must be pre-deployed (using AWS CloudFormation StackSets, or otherwise) across every member account in the Organization.
- The usage of the services listed above must not be blocked by a Service Control Policy (SCP).
The entire solution is deployed with an AWS CloudFormation stack, which is hosted on our GitHub here. The first part of the solution, deployed as a StackSet, is named TGW_SecDataOps_Roles_CFN.yml. The second part, which is deployed in your centralized collection Account, is named TGW_SecDataOps_Collector_CFN.yml. Once you have completed the deployment, proceed to the next section to learn how to manually execute this solution and ensure it is working properly.
Manual Execution
After deploying the entire centralized Transit Gateway logging solution, you may need to execute both the Lambda function, and AWS Glue crawler, manually.
First, navigate to the AWS Lambda console and locate the deployed function, the default name will be tgw_central_flowlog_configurator_lambda. Select Test, enter in an empty set of curly braces ({}), and select Invoke as shown below.
This process can take several minutes depending on the total amount of Accounts, Regions, and Transit Gateways in your environment.
After successfully executing the Lambda function, monitor the created bucket for Transit Gateway flow logs being delivered. Once the first few logs files are created in the bucket, navigate to the AWS Glue Crawlers console and locate the crawler created for this solution, the default name is tgw_central_flowlog_configurator_crawler. Select it and on the top-right select Run Crawler as shown below.
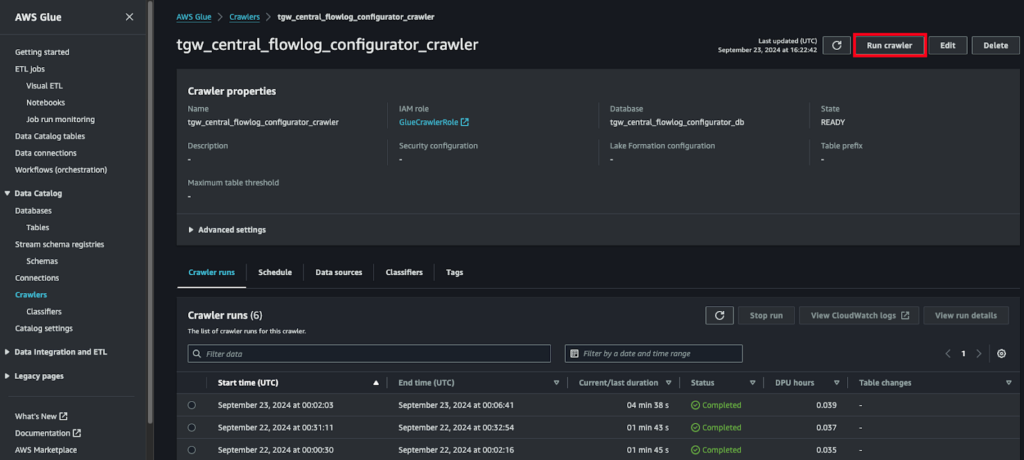
Once complete, the Glue crawler will add all identified partitions in the TGW flow logs and register a table in the Glue data catalog to submit queries against. A new database is created with the CloudFormation stack, named tgw_central_flowlog_configurator_db by default. The table will have its name autogenerated for you to write queries against.
As the partitions are discovered by a Glue crawler, the table uses partition pruning, you do not need to explicitly use any partitions. The more specific the partitions, the better your queries will perform, this allows Athena to prune down to very specific S3 paths to read the specific objects there. Since the Parquet files are read optimized, the read speeds are even faster, compared to the same amount of objects in a path that are text or CSV files.
Conclusion
In this blog you learned about analyzing Transit Gateway flow logs in multiple ways. You learned how to use Amazon Athena SQL queries to create tables of existing Transit Gateway flow logs stored in text files. You learned how to create simple tables as well as tables with partition projection to improve query performance. Finally, you learned how to deploy an automated solution to centrally collect Transit Gateway logs and store them in read-efficient formats.
The solution will work for moderately sized environments (approximately 25-50 AWS accounts) due to the sequential nature of the inventory collection and the timeout of a Lambda function. In the future, we may release a V2 of this solution that utilizes containerized workloads and parallelized, multi-processing. Please open an Issue on the GitHub repository if that solution is of interest to you. Until next time…
Stay Dangerous