
With increasing costs of sending high-volume data sources into SIEM, organizations have switched to storing their EDR data into Amazon S3. It provides a scalable option that can easily accommodate the growing volume of EDR data generated by an organization’s endpoints. In this blog, we will discuss why that is happening, what new problems it creates, and how to solve them to make Amazon S3 based security storage an effective strategy for your organization’s endpoint data.
Note: I am using EDR here as a generic term for Endpoint Detection & Response products like CrowdStrike Falcon, VMWare Carbon Black, SentinelOne, Palo Alto Networks Cortex, (name your favorite EDR)…
SIEM is no longer practical for EDR data
SIEM has gone through such cost overruns that organizations are doing anything and everything to reduce data volumes. The first data source that gets moved out is EDR data because of its high volume. Correlated SIEM alerts from SIEM rules firing on this data were low-fidelity noise when compared to higher quality EDR alerts. So this move-out actually provided some relief from unnecessary SIEM alert fatigue!

Leaving data in the EDR vendor’s SaaS long-term had the same problems (and more!)
The easy option could have been to just leave the data in the EDR vendor’s SaaS long-term, however there are several issues. While the first two have been problems for a while, the third has newly been reported by analysts.
- You are not exactly saving any costs since you have to pay significantly more to have your data hosted long-term with your EDR provider.
- While the data is accessible to analysts, it is limited to searching/visualizing in your EDR vendor’s console. You can’t perform any custom analytics or processing without manually transferring it into a data lake you control.
- Since you signed off your data to your EDR vendor for the long-term, you have no idea and no control over how they are going to use it for their own purposes. Don’t be surprised to find out it is being sent to third-parties, for example, to train external LLM models.

Amazon S3 emerged as the flexible, low-cost option under the organization’s control
Amazon S3 is now the home-grown security data lake that has become a best option for many enterprises. In a previous blog, I talked in more detail about cybersecurity teams storing security data in Amazon S3. For this blog, we are specifically discussing EDR data because that is the largest data source security teams are actually putting in this S3 based data lake.

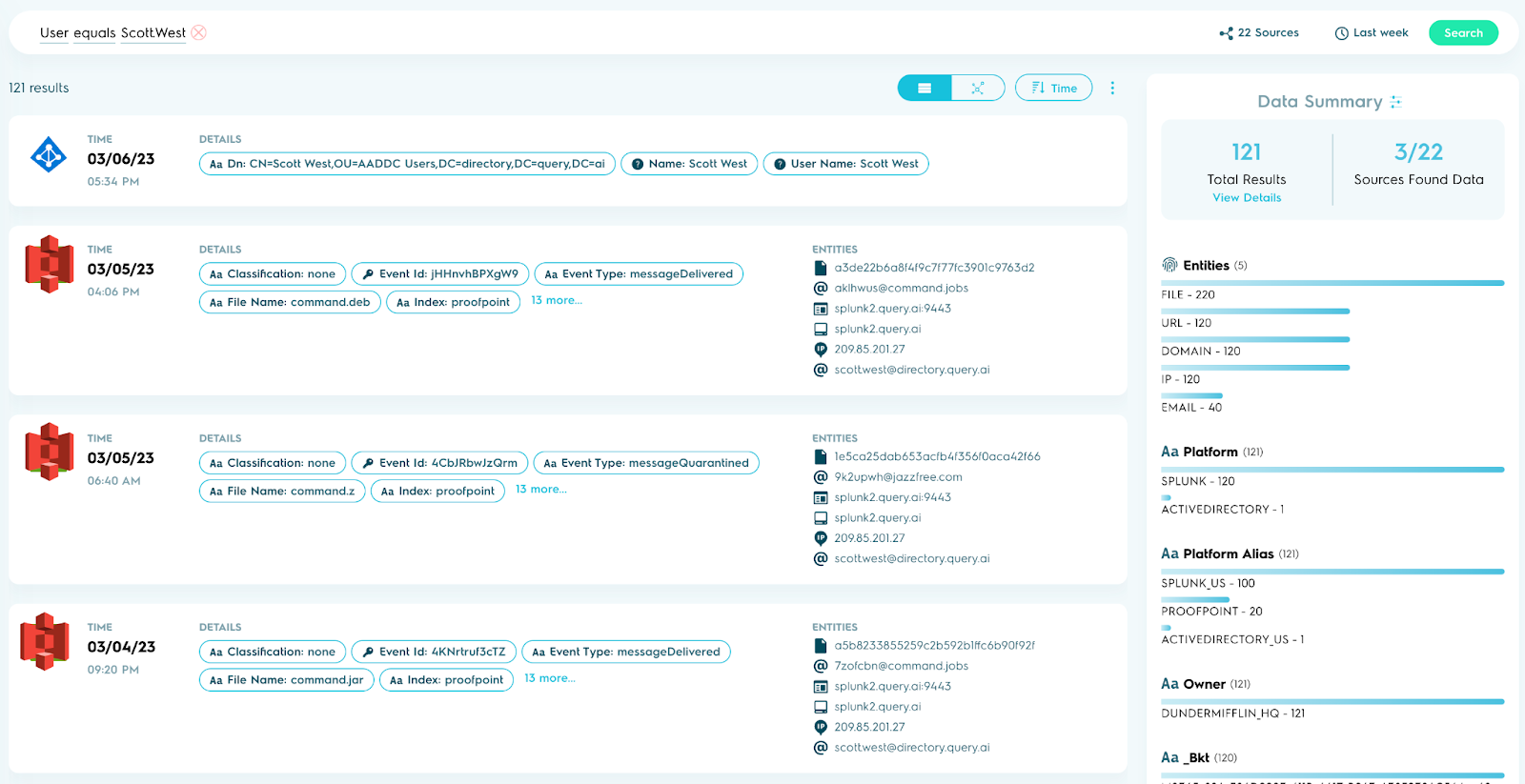
But security analysts can’t directly use data stored in S3 — they need a Security Console.
While moving EDR data to S3 lowered storage costs, there was no way for analysts to easily interact with that data. Common investigations, like malware file hash investigations, require interactive visualizing and pivoting, for example: to find out which machine got infected first, who was the user, what was the entry path, which other machines are potentially infected, etc. In my previous blog, we discussed a concrete example with technical steps to setup and query the data via Amazon Athena’s SQL interface. But SQL is practical only for one-off engineering needs vs the needs of security analysts.

Query your S3 data in minutes with Query’s Open Federated Search for Security
In an effort to better understand our customer base, Query recently conducted interviews and surveys with security professionals at over 100 organizations. We found that more than 75% of those surveyed are switching to store their EDR data outside of their SIEM largely because SIEM is too expensive, and storing long term data in your EDR has its own evolving challenges. Depending upon the cloud platform of the organization, the most popular choice was Amazon S3, followed by Azure Blob Storage, and GCP Cloud Storage.
From the organizations storing EDR data in S3, we heard that analysts need a more practical interface that lets them visualize and interact with that data to be productive and effective. They need a Security Console that empowers them to search, visualize, filter, investigate, and pivot over the S3-stored EDR data. They also need to correlate that data with additional sources like Active Directory, Okta, etc. for Identity, and VirusTotal for Threat Intelligence.
Using the interviews and surveys as our guide to understanding the problems of security analysts and their desired solutions, Query built exactly that console. Query lets you search through multiple data sources residing in Amazon S3 without moving or duplicating the data. It only takes a few minutes to be up and running since there is no “install” or data migration needed. Just point Query to your S3, configure access, configure the data model, and you are ready to search, visualize, filter, investigate, and pivot. You get complete control of your data and we become your window to your data.
Summary and Next Steps
We will let Gru summarize since he came up with the idea to store and query from S3 in the previous blog …
