It’s the URL, stupid (me)!
Consider a scenario. You are in a miserable situation where you accidentally clicked on some phishing link or scam URL. A long time ago, when the web was safe, and viruses, trojans, and worms were transmitted only by EXE or BIN files, we could rest assured that the virus scanner protected us.
Now, the web is the purveyor of all things good and evil. Smartphones have become the norm rather than the exception. The individual security measures (windows, IOS, etc.) are only as useful as there latest update, and maintaining the amount of tech we each possess up to date is difficult. But the most common denominator is the URL centric web. All devices have Internet access and thus are vulnerable to the latest threats.
Think of the email before spam abuse. There used to be open relays everywhere, and anyone could send emails using a 10 line shell script using SMTP command verbs. Today that is impossible since email abuse has turned people away from everyday email. Even when you need to use email for work, most of one’s inbox is someone trying to sell you something or market something. Every piece of traffic that humans originated on the Internet has a URL, so let’s look at new-age security measures to help protect you.
Let’s safely examine a URL
We can’t trust all the URLs friends and family send over as many social media sites, emails, and whatnot have been compromised. Most likely, each of us has received a malicious URL coming from close friends’ or family members’ accounts. What choices do we have?
(a) ignore and appear rude (b) pray and click (c) investigate further before clicking
For the diligent ones amongst us, what is the best way to investigate further one may ask?
One option is a background scanner that looks at each website’s health the URL points to without eyeballing it manually. Wouldn’t that be nice? Nowadays, it is not the OS on your desktop but the browser web access that dictates your computer health and network resource usage. By scanning a URL using back-end tools like UrlScan, we can get a lot of information about how the website looks and works, including its dynamic content, video, images, etc.
There are several tools but let’s start with UrlScan. UrlScan is a Microsoft tool that analyzes the text content and the dynamic javascript and DOM structure to filter out unwanted websites. The idea is that if a website URL is unsafe, a 404 (not found error) is returned, thereby making the click work safely even with automated software-based clicks and accesses.
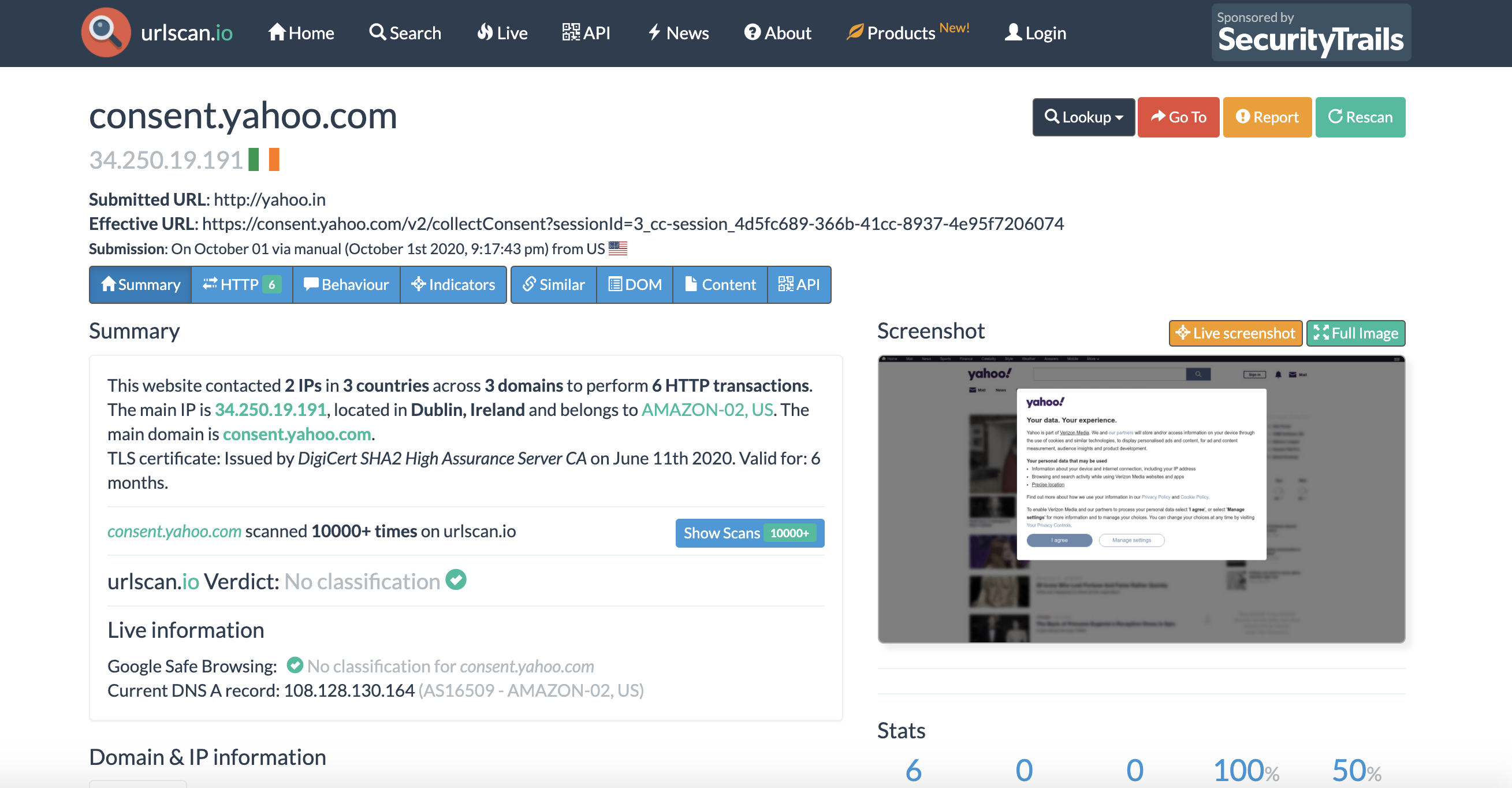
Another such tool: urlscan.io, cans and analyses websites. When a URL goes to urlscan.io, an automated process browses it (like a regular user) and records the activity on that page. This process discovers the domains and IPs contacted, the resources (JavaScript, CSS, etc.) requested from those domains, and additional information about the page itself. urlscan.io will take a screenshot of the page, record the DOM content, JavaScript global variables, cookies created by the page, and many other observations. If the site targets the users of a familiar brand tracked by urlscan.io, it is highlighted as potentially malicious in the scan results.
I have seen plenty of open source tools that use UrlScan for various purposes, even to break down an HTML file into links inside the mutt email client on Linux. UrlScan operates using a synchronous call method in which you wait for results when you invoke the scan. But it is commonly used by submitting a URL and then polling for scan results later. Due to the high traffic and owing to the service being free, UrlScan requires you to obtain a free API key for the scan service and is hassle-free in my experience. But to use the service, we must implement exponential backoff and play like a good citizen and not abuse their server resources.
Here are some examples to get you started.
I am using urlscanio, a github project ( https://github.com/Aquarthur/urlscanio ), for a Python CLI for urlscan.io. First you export the API key like this:
$ export URLSCAN_API_KEY=<key>
$ urlscanio -i http://yahoo.in
Scan report URL: https://urlscan.io/result/dc7e62d6-8738-4fd2-bddf-6b9c42b8ff2a/Screenshot download location: screenshots/dc7e62d6-8738-4fd2-bddf-6b9c42b8ff2a.pngDOM download location: doms/dc7e62d6-8738-4fd2-bddf-6b9c42b8ff2a.txt
You also have the --submit and --retrieve commands for the offline operation and batch requests.
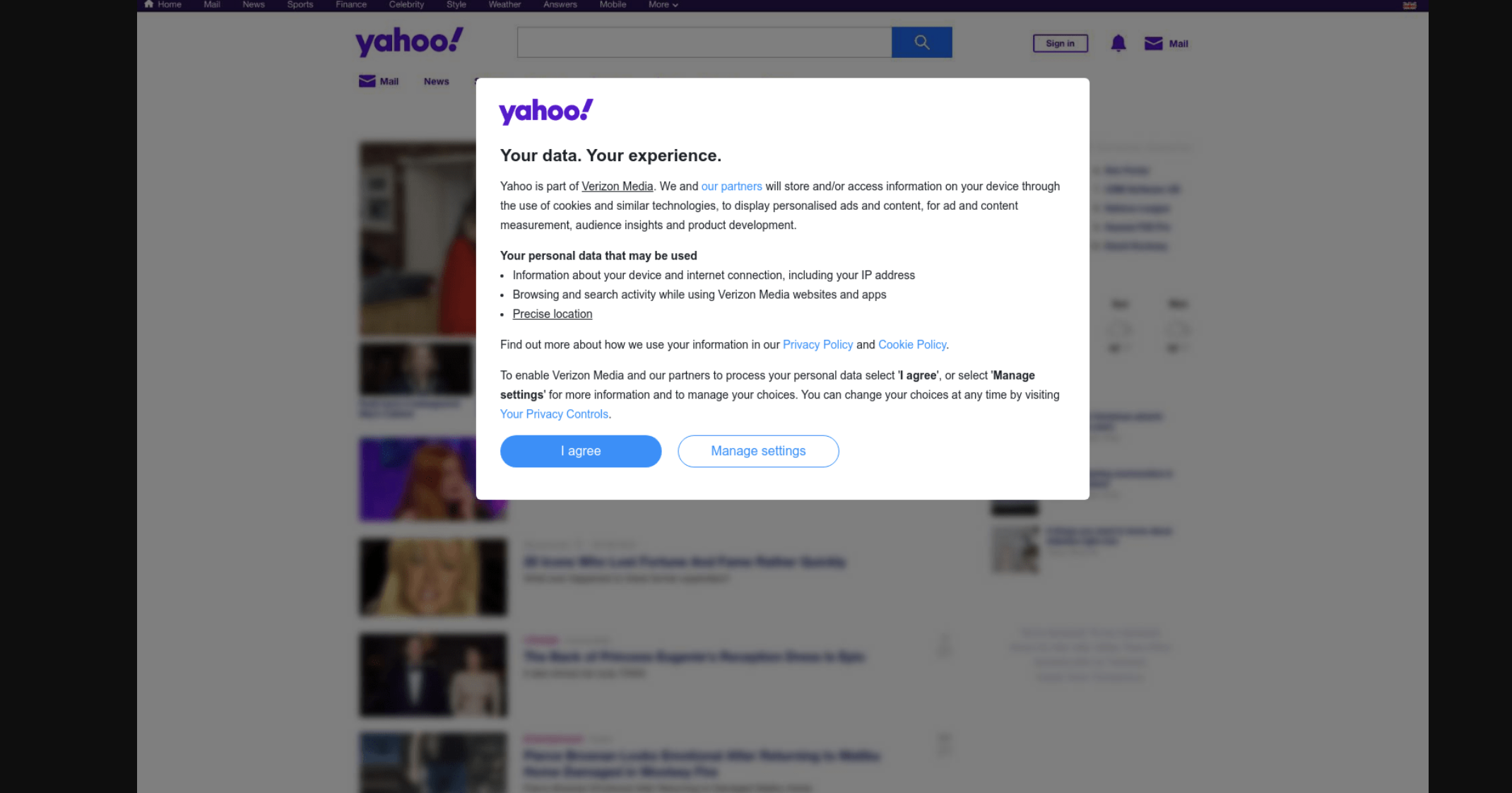
If you look at the screenshots you see this.
And the scan URL shows this: