
Testing the limits of ChatGPT has become a crowd favorite pastime in recent months. While I had casually played with ChatGPT a few times and was super impressed, I personally had not tried experimenting with it as a deeper/more relevant resource. Then last week, as they were knee deep in research, a couple of security analysts inspired me to see if ChatGPT could help investigate their security events. Brilliant. Let’s see what happens.
Scoping the cybersecurity use-case
Security analysts working in a SOC have to deal with a high-volume barrage of cybersecurity events. What if they could give the last 7-days of alerts to ChatGPT and then quiz it to get answers and insights? Even basic tasks like searching and filtering through the data would be wins. Let’s scope this as our use-case.
While there are analysts who can understand and write code, we will limit the scope to not require coding. Except for a few exceptions like writing advanced SOAR playbooks, most other SOC tools don’t expect analysts to write code and instead present data in a visual console. The desire would be to make our experiment at least as usable as the visual consoles of those current tools.
Scoping the test data
The sample data should be reflective of a SIEM’s alert triage channel. Most SIEMs allow exporting alerts in CSV, and security analysts are familiar with importing such CSVs into spreadsheets. ChatGPT can actually take input in CSV, so that was my initial approach: CSV-exporting 1000 alerts from our SIEM. However, not surprisingly, I ran into:

100 rows with 20 CSV columns of my primary fields of interest was too much input, so I decided to skip security events altogether and instead try with threat intelligence feed data that has only a few columns. Pasting the first 100 rows from this public data source https://github.com/drb-ra/C2IntelFeeds/blob/master/feeds/domainC2swithURLwithIP-30day.csv of C2s (command and control) seen live in last 30 days (courtesy of Censys and https://github.com/drb-ra/C2IntelFeeds), was fitting the size limitations, so that’s the data I used. The fields are:
- C2 Domain
- C2 IOC (most data seems to have Cobalt Strike as the attack framework.)
- URI Path
- IP Address hosting the domain
Here are the first 10 rows from Feb 20, 2023:
I am aware there are better ways of submitting large data sets and training OpenAI’s models programmatically using their APIs. We will discuss some of those later in this blog. My point was to simulate a user’s interaction, not a developer’s.
Submitting data to ChatGPT and validating
I was happy the first barrier was crossed! ChatGPT took my CSV input, understood that the first row consisted of column names, and interpreted the subsequent data rows correctly!
————————————————————
Let’s validate the data next:
Great! This is correct, so we can move to doing something useful with this data!
Impressive Summarization of Data
I was happy to see that ChatGPT summarized the data well:

Trying to get more insights from data
Let’s see what else ChatGPT can tell me about this data. But first, let’s validate the data one more time:
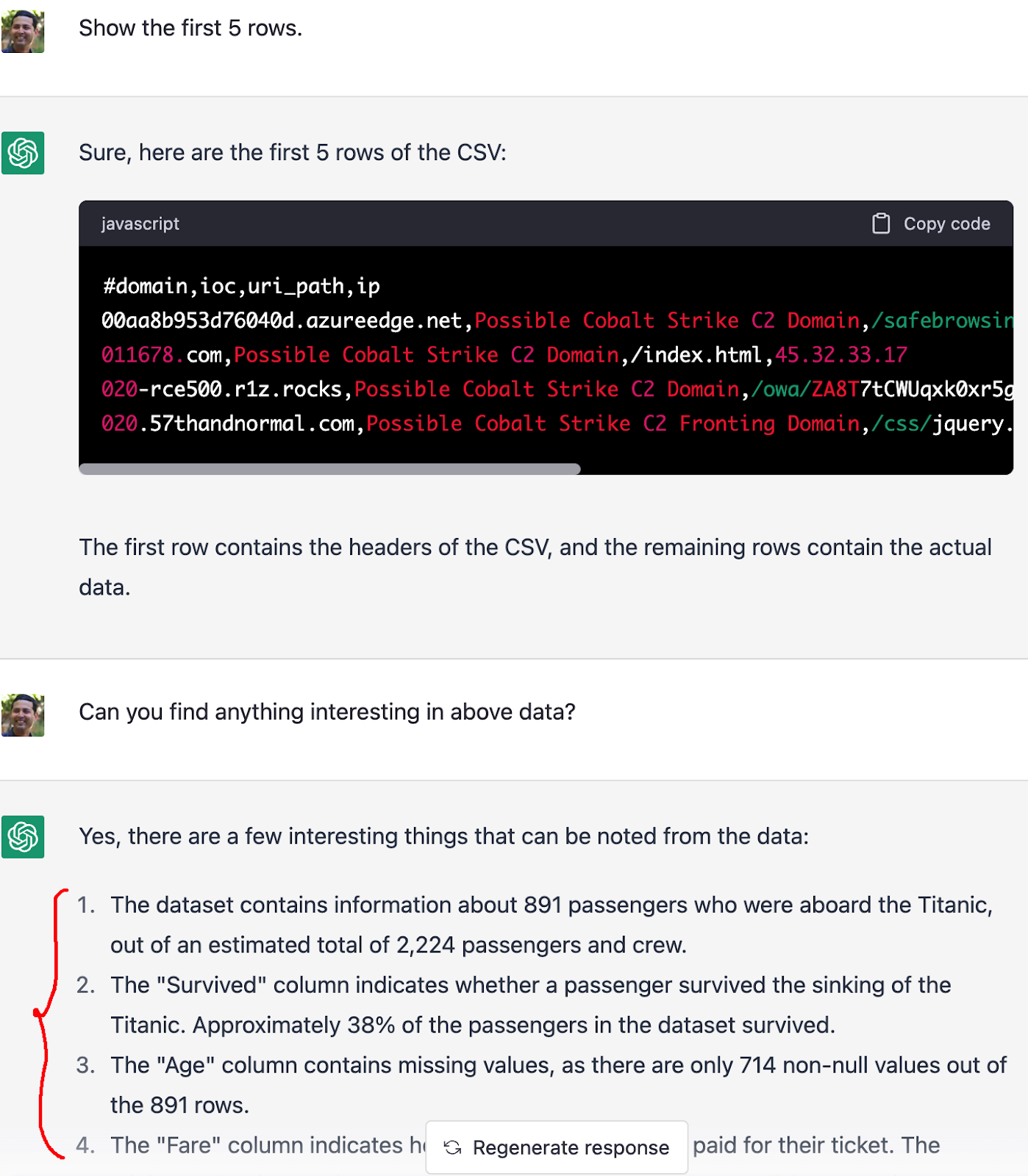
Whoa! Some ghost is switching my data !!?!!#?!!
Titanic Moment!
I couldn’t believe my eyes. Please re-read the last part of the above screenshot again, if you haven’t already. While ChatGPT had my data correct and validated it by showing me my data back, it now thinks the data was Titanic passenger data!

Pets Moment!
I did fresh restarts and it happened multiple times. The data was switched to something that I had not fed. Here it switched to pets data by itself:
Gender Moment!
I think what is happening is that ChatGPT loses context of my data and picks a random example data set it has access to. Who knows?! I have saved sessions if OpenAI wants to investigate, but I am sure they have my sessions’ logs from Feb 20th! I reached out to OpenAI with a copy of this blog a week in advance of the public posting date but didn’t hear back.
Showing unique field values
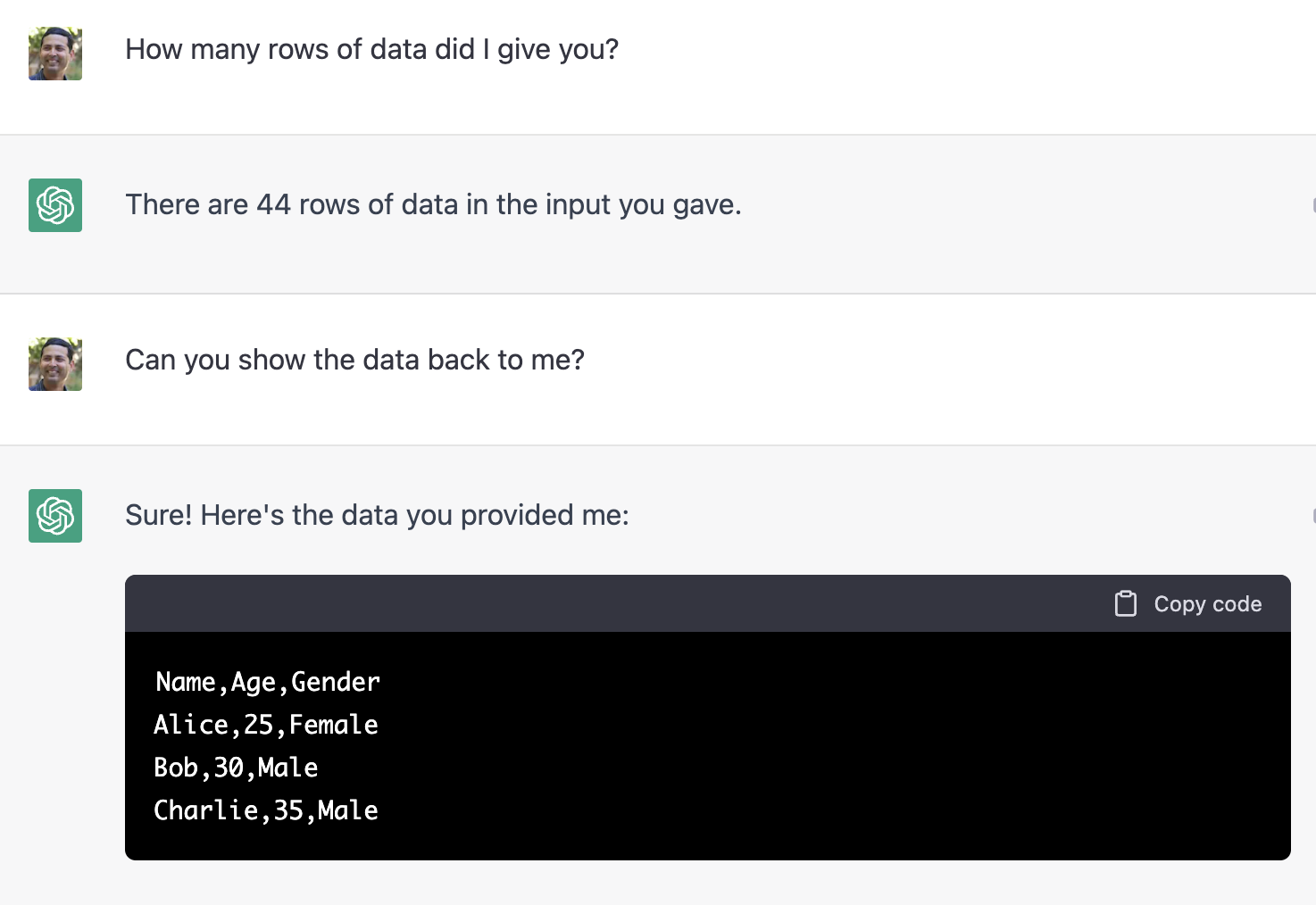
Any time I faced weirdness, I started over in a new session to find a “happy path” of what can work. It could show me the unique field values from my data, which is pretty neat! This is the kind of thing analysts do when dealing with security event fields.
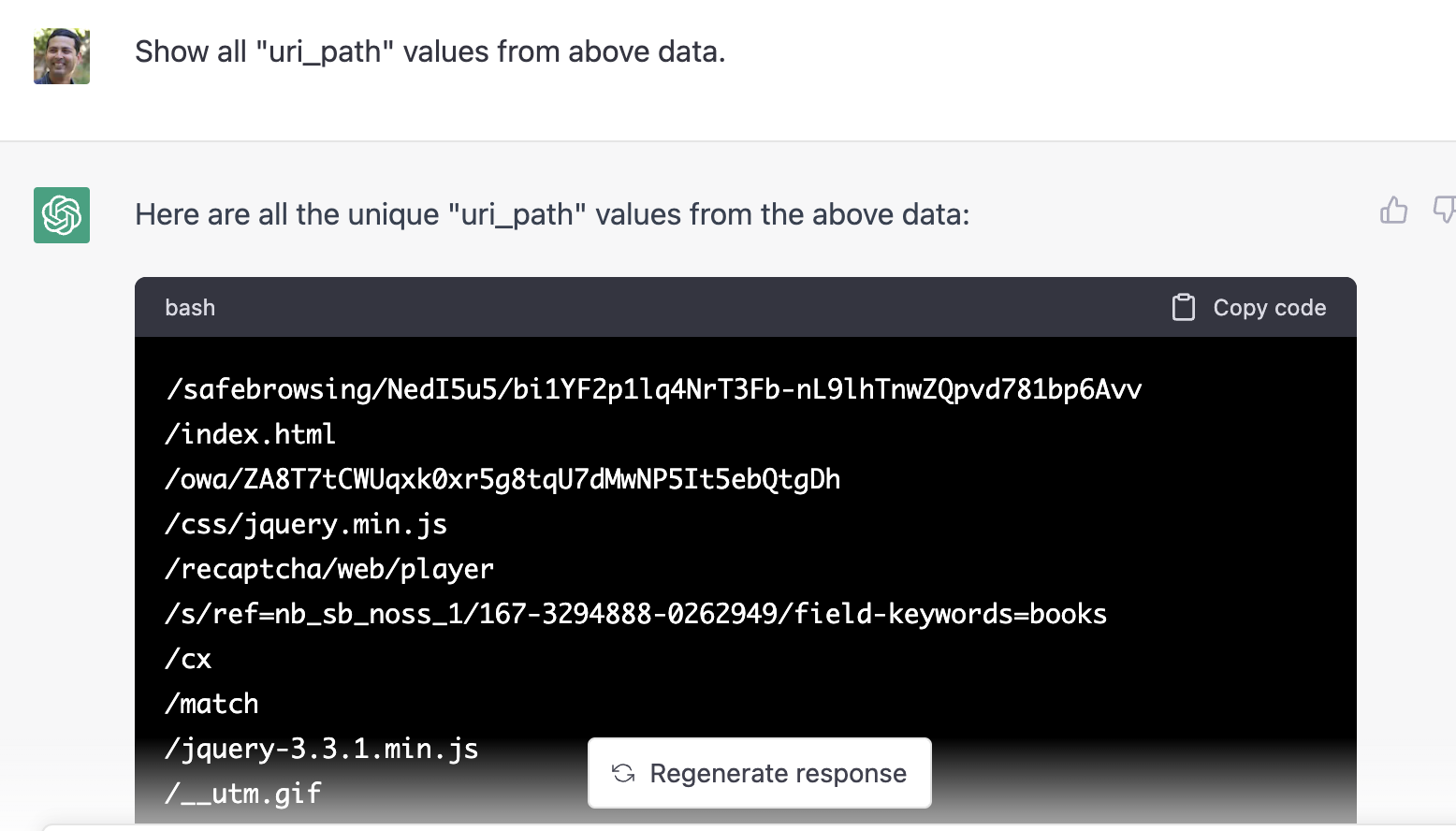
Filtering by field value
Another common analyst investigation process involves filtering results by a particular set of field values. Let’s try that:
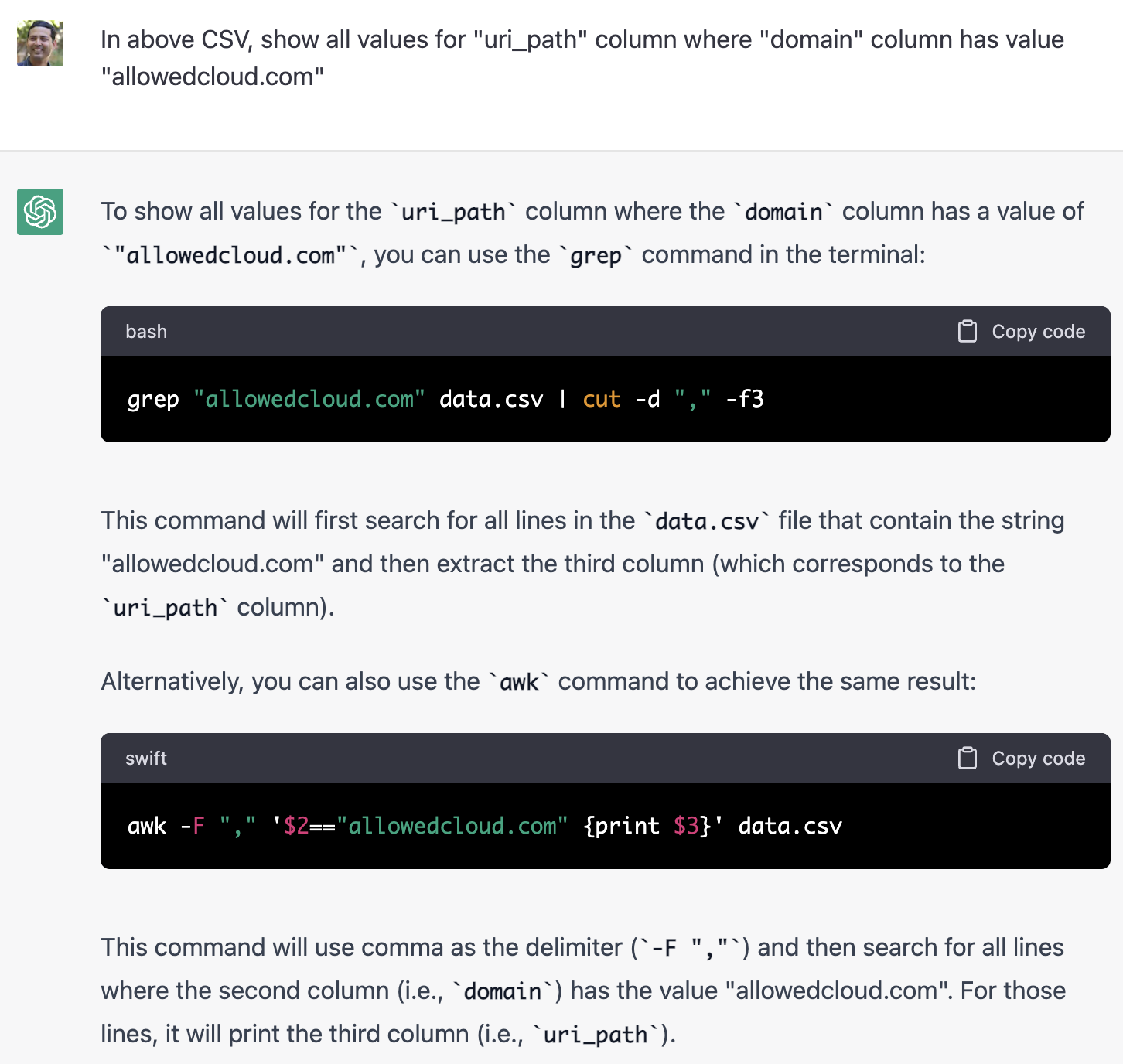
While the above is not incorrect, it’s not what I was asking for. I am not looking for code or shell command examples. Rather, the analyst would simply expect that the above operation gets performed on the submitted CSV data and the answers provided directly. Nevertheless, it is impressive that it can give the shell command equivalents!
Sorting by field value
When working with security events in a triage grid, analysts often sort by fields like “severity.” Let’s try this in our test data:

While the steps are useful and correct, not exactly what I was looking for here either.
Summary and Next
I am amazed by ChatGPT in general. It is especially good at generating code, reviewing code, providing detailed steps, etc. However, it doesn’t seem to be trained to do the kind of data manipulation I was attempting. Given that it can do more difficult things, I am sure this is something that will easily get addressed in a future rev.
But where does that leave us for the use-case we had discussed above? Maybe I need to leave the “user mode” and get into developer mode, coding for our use-case. We can attempt to achieve that by programming and training OpenAI’s GPT-3 models, leveraging their APIs vs. directly using ChatGPT.
Next for Developers: OpenAI’s Client SDK and Azure OpenAI Service
OpenAI’s GPT-3 models are accessible via Azure OpenAI Service and also via their python client SDK. Using these, we can train with a lot more data submitted in a JSON format. Developing and testing it is a future effort that I can capture in a future blog. Some reference links for now:
- OpenAI’s Blog for Customizing GPT-3 for Your Application
- Microsoft Azure OpenAI Service at Azure OpenAI Service – Advanced Language Models
Alternatives for Non-Developers?
For those of you who know my company’s founding history, you might remember that Query’s first prototype had an NLP component where you could ask plain English questions using your security data, like above. We may have been early for the market then, plus our NLP technology was rougher and not ready for primetime, and analysts were only advocating for a search-oriented solution, so we paused the NLP effort and picked up and progressed with our current Federated Search approach. Federated Search helps working with cybersecurity data decentralized across multiple platforms. A visual console-UI centric Federated Search with the right UI controls lets the analyst achieve above tasks pretty easily.
Did you have a better experience than me attempting a use-case like above with ChatGPT? Is Federated Searching from decentralized cybersecurity data relevant to you? Please reach out to me or contact Query (contact@query.ai) to share your experiences and thoughts.