
Current SIEM architecture is becoming untenable with increasing costs and limited visibility.
The dream that cloud SIEM would magically make things easy didn’t play out. In fact, with security data now everywhere, it actually increases costs. Unfortunately, most of the revenue SIEM vendors get is going to their cloud providers, putting them in a tight spot with limited room to manage costs. Maybe the vendors secretly wish they had stuck with on-prem SIEM where the customer was paying for storage! (Disclaimer: This is just my personal opinion from being part of the SIEM world for the past 20 years. I am thankful to my colleagues at Query for letting me share my thoughts directly on our website!)
In any scenario, it’s the customer left to hang out to dry with the SIEM bill.
As a result, security teams are now withholding important data from their SIEM – data sources like EDR, DNS, Firewall, Webproxy, DHCP, Flow data (Netflow, VPC Flow), Cloudtrail, SaaS, etc. Unfortunately, improving the cost problem created a visibility challenge.
The current SIEM, wherever it lives, cannot solve this dual cost and visibility problem. That is unless there is a foundational architecture shift that redefines what a SIEM is!
My time to imagine…
NOTE: This is a big topic, but to keep the blog small I am inserting further reading references.
Let’s imagine a new architecture…
1. Break apart SIEM Console, its collection pipeline, and its storage.
You might love your SIEM vendor’s console, but you might hate being forced to use its collection pipeline, its storage, its poor performance, or its data volume licensing model. Unfortunately, our hands are often tied to using the same vendor for it all. No wonder – replacing SIEMs is a complex, multi-year project, so dreaded that it leaves security teams held hostage to whatever systems the organization is currently using, even if it no longer serves them well.
The solution is to separate out and use the most suitable component based upon your environment – a relevant security console, the most suitable collection pipeline, and the most suitable storage. These come from different vendors and are environmentally dependent, such as on what cloud provider you are using, etc.
Reading:
- How security data pipeline is ripe for change
- How to have security console from a different vendor for data stored with another vendor (use Amazon S3 or equivalent for cloud blob storage)
2. Decentralize your collection/storage, keeping it near to source. Leverage each cloud account’s blob store.
You don’t want to be moving big data from one cloud account to another, just because your SIEM is in the other account. The new architecture should work with data separated across cloud accounts, across same/different cloud providers, and also across on-prem locations/geographies.
The storage options should be flexible and heterogeneous, based upon logistical choices for that data source. You may choose different storage options based upon usage patterns or optimal cost.
Reading:
- Great blog by Dr. Anton Chuvakin on how the log centralization architecture should change – Log Centralization: The End Is Nigh.
- Steps to use Azure Blob as a storage choice, if you are in Azure
- Steps to use Amazon S3 as a storage choice, if you are in AWS (same blog mentioned in the previous section above).
3. Access SaaS data just-in-time leveraging APIs.
Mid and large organizations are using 50-100 SaaS applications where the data is hosted by the respective vendors. Fortunately, mostly every vendor now has some form of APIs to access that data. In the new security architecture, we would want to leverage that existing hosting vs duplicating it. (Well, you may still need to host the historical data, if the vendor’s hosting time is less than your needs.) The advantage of such direct access is that you get live and up-to-date information from the source of truth.
Reading:
- An integration example here of CrowdStrike’s SaaS data being accessible/available over APIs.
- An alternate example of how AWS-hosted SaaS service components’ data can be made available here.
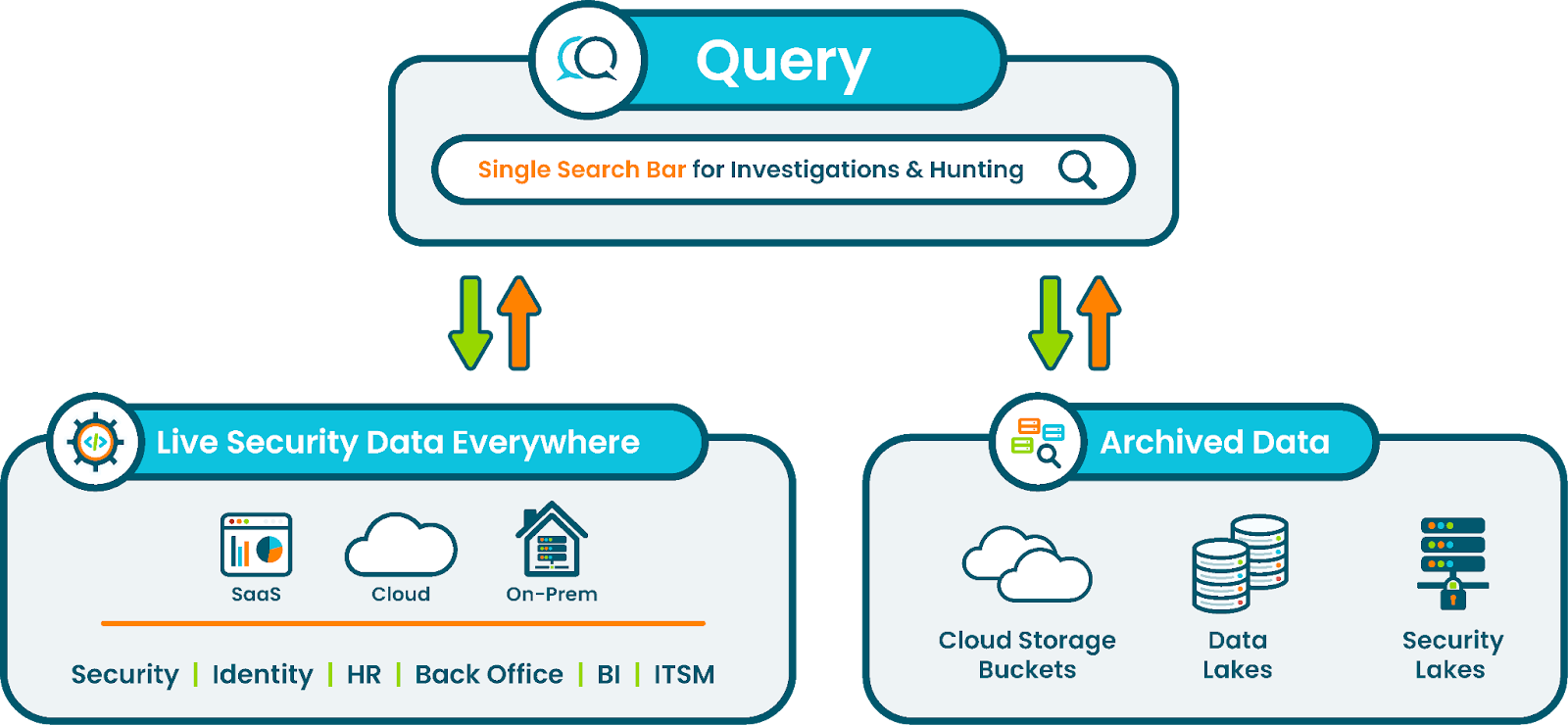
4. Connect above heterogeneous stores using open federated search.
In the above sections, we talked about decentralized collections and storage. But how do we bring it all together into a single SIEM console?
We will use open federated search for it. With federated search, you can connect all your data sources, particularly your cloud storage discussed earlier, which would have archives from many security and security-relevant sources. The federated search console can visualize your data both standalone, and also from the context of your SIEM.
Reading:
- Learn more about open federated search in this whitepaper.
- See here for how to bring open federated search into Splunk Console.
5. Normalize and correlate data from across platforms for powerful contextual lookups.
Having a solution that can only do basic federated searches is not enough either. The new architecture should leverage federated data sources, understand their respective data schemas, normalize query results, and correlate them from across platforms so that proper dependency lookups can take place. Otherwise, the analyst is again running too many manual searches, and linking separate results in a notepad/spreadsheet.
Reading:
- OCSF is a hierarchical cybersecurity data model emerging as an industry standard. Learn more about it here.
- Read this whitepaper on how to evaluate open federated search solutions that can normalize, correlate, and do automated contextual lookups.
Voilà!
The architecture changes we discussed don’t even look like a SIEM anymore. Does it mean the current SIEM is not relevant? No, not at all – it is still relevant for the real-time capabilities around which current SOC operations have been built. Solutions based on the new architecture complement the current SIEM architecture by letting the current SIEM focus on real-time monitoring/alerting, while taking the historical/investigative aspects off of it.
Today, they definitely co-exist, and add value to each other!
